 ¿Cómo se importa en Therefore™ un lote de archivos cuyos datos de índice se incluyen en un archivo de datos adjunto?
¿Cómo se importa en Therefore™ un lote de archivos cuyos datos de índice se incluyen en un archivo de datos adjunto?
1.Antes de crear un perfil se necesita una categoría adecuada en Therefore™ en la que se puedan guardar los documentos exportados. En esta etapa deberá realizar una planificación cuidadosa, ya que una buena indexación mejorará la gestión posterior de los documentos.
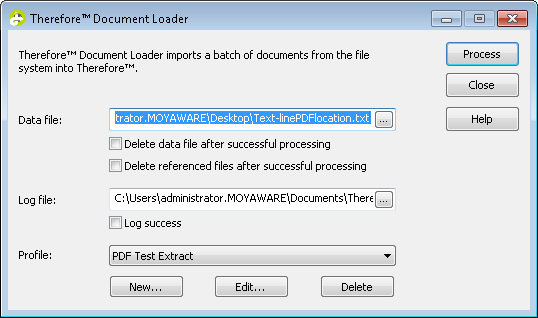
2.Inicie Document Loader y en Perfil, haga clic en Nuevo.

|
También puede crear y administrar perfiles en Therefore™ Solution Designer.
|
3.Se abrirá el cuadro de diálogo Perfil. Introduzca elNombre de perfil. El paso siguiente consiste en configurar un extractor de datos para obtener los datos de índice del archivo de datos. Haga clic en el botón Examinar del Extractor de datos:
Elija Extractor de datos de XML.
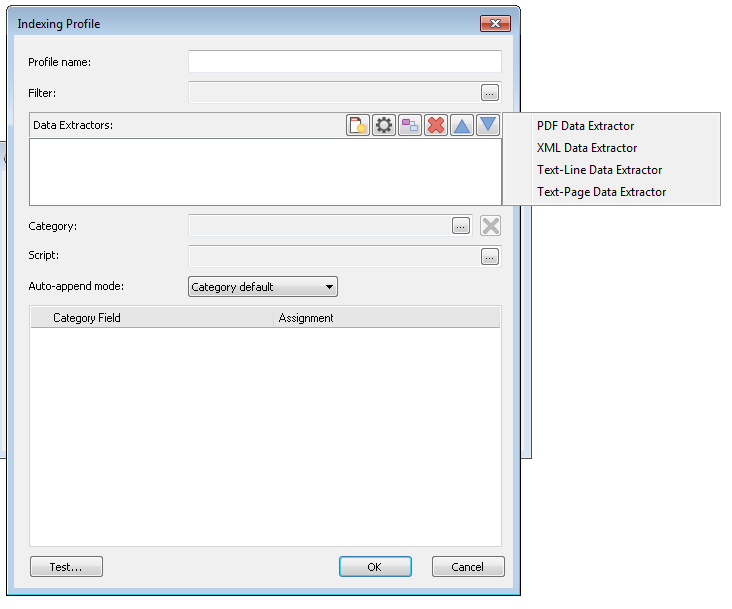
Se abrirá el cuadro de diálogo Extractor de datos con una vista previa del archivo XML. Ahora es necesario definir la etiqueta XML que define el documento. En este caso, la información del documento se encuentra entre las etiquetas <Document> ...</Document>. En el panel izquierdo, haga clic en el nombre de la etiqueta Document. Cuando se define esta etiqueta, el Extractor de datos de XML puede extraer todas las etiquetas de campos de índice del documento que utilizaremos posteriormente para asignar los campos de categorías.
|
Los archivos XML grandes pueden tardar mucho en cargarse y actualizarse. En estos casos puede realizar una copia del XML y eliminar todos los documentos menos uno. A continuación, use este nuevo XML para crear el perfil, pero recurra al original cuando use el perfil final.
|
Antes de hacer clic en Aceptar también debemos averiguar la etiqueta que define los archivos de referencia que componen el contenido del documento. En este ejemplo puede ver un archivo "Invoice2009_002.pdf" y se encuentra entre las etiquetas <FileName>Invoice2009_002.pdf</FileName>. Tome nota de esta etiqueta para utilizarla en el siguiente paso del diseño del perfil. Esta etiqueta no se necesita en las situaciones en las que el archivo de datos XML sea el archivo que se debe guardar.
|
Elija Extractor de datos de línea de texto.
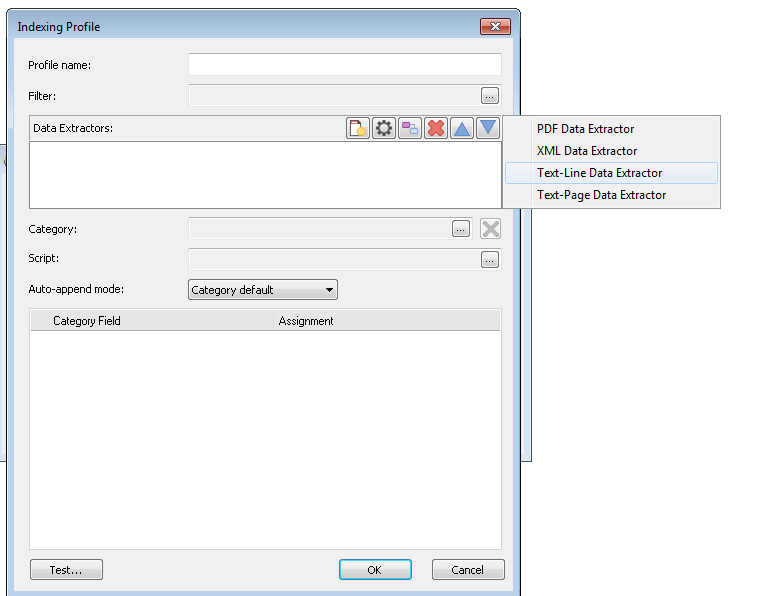
Se abrirá el cuadro de diálogo Extractor de datos con una vista previa del archivo de texto. Especifique el Delimitador y se introducirán automáticamente los números de pieza con valores. Introduzca nombres para los números de pieza (campos de índice) que desea extraer. En este ejemplo, Nº. de factura también se utilizará como salto de documento y, por tanto, podemos configurar esto como Al cambiar. También puede configurar la opción Comillas según la configuración del archivo de texto. Siga definiendo todas las demás partes que contienen los datos de índice que requiere.
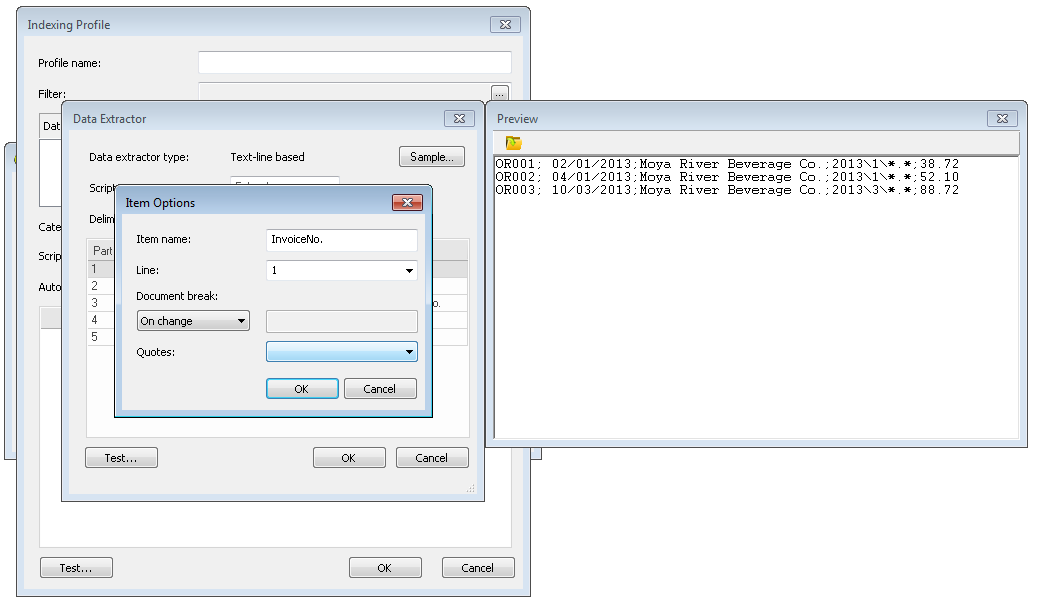
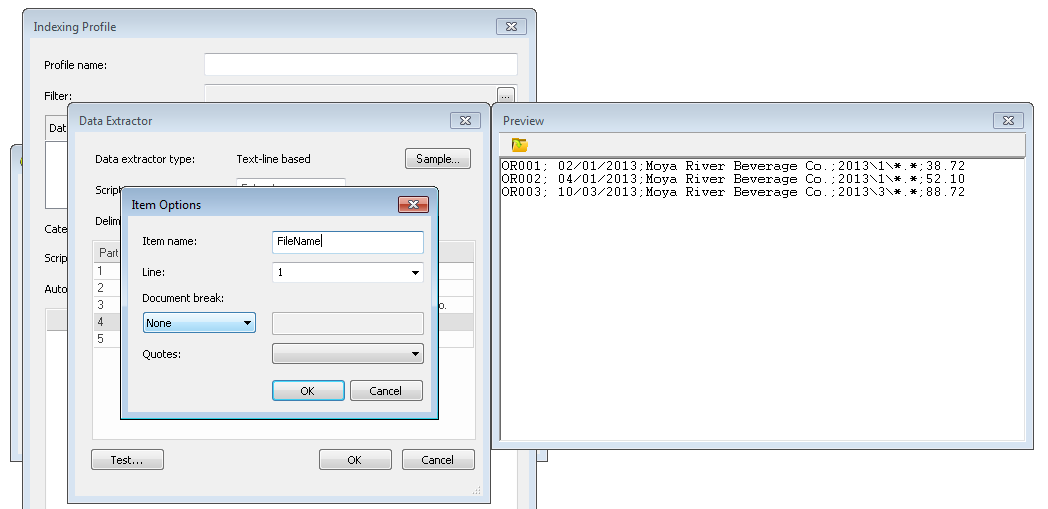
Después de definir todos los campos de índice, también debemos nombrar la parte que define los archivos de referencia que integran el contenido del documento. En este ejemplo es la cuarta parte y la llamaremos Nombre de archivo. Cuando termine, haga clic en Aceptar para cerrar el Extractor de datos.
|
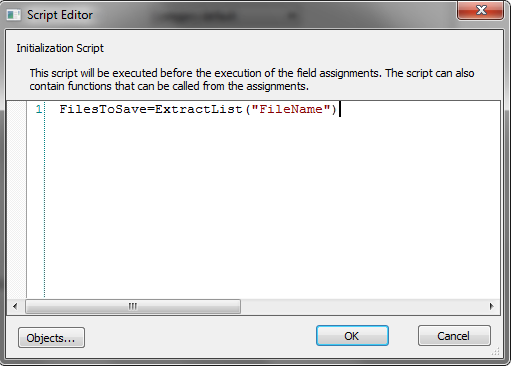
6.A continuación, haga clic en el botón Examinar del script e introduzca el script: FilesToSave = ExtractList("FileName") donde FileName es el nombre de la etiqueta del paso anterior. Es importante utilizar ExtractList y no solo Extract porque un documento puede contener múltiples archivos referenciados. Haga clic en Aceptar para cerrar el cuadro de diálogo del script.
|
Para aclarar este paso, ofrecemos a continuación ejemplos de scripts incorrectos:
FilesToSave = Extract(“FileName”): solo extraerá el PRIMER archivo de cada documento. Si hay varios archivos, no funcionará.
FilesToSave = Extract(“FileNames”): no importará ningún archivo.
FilesToSave = ExtractList(“FileNames”): no importará ningún archivo.
El ÚNICO correcto en nuestro XML de ejemplo es FilesToSave = ExtractList("FileName")
|
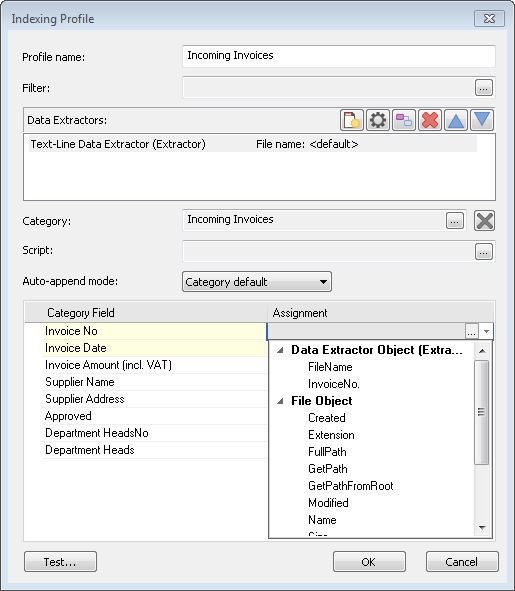
7.Seleccione la Categoría donde deben guardarse los documentos. Si se ha configurado Añadido automático en las propiedades de la categoría, puede especificar el modo Añadido automático de forma diferente que la categoría predeterminada. Ahora pueden asociarse los campos de la categoría. Haga clic en la lista desplegable y elija el campo de índice correcto en la lista de campos de índice extraídos que definimos con el Extractor de datos.
|
 Gestión de formatos de fecha Gestión de formatos de fecha
Cuando el formato de fecha de los documentos que se van a importar difiere de la fecha del sistema operativo en el que se ejecuta Document Loader, puede utilizarse la función ToDate. Por ejemplo, si los documentos tienen una fecha con el formato DD.MM.AAAA pero el sistema utiliza otro formato, puede utilizar en la asignación: ToDate(Extract("Invoice Date"), "DD.MM.YYYY").
|
Elementos de línea
•Para importar elementos de línea se requiere un script. Por ejemplo, para un archivo de datos XML con una tabla llamada "myTable" con dos columnas: "Text" y "Number".
<myTable>
<Text> Text1 </Text>
<Number> 1 </Number>
</myTable>
<myTable>
<Text> Text2 </Text>
<Number> 2 </Number>
</myTable>
En las Asignaciones, utilice: ExtractListTable("Text,"MyTable") y ExtractListTable("Number","MyTable")
|
Extraer información del contenido del PDF
1.En primer lugar, defina un perfil de indexación (utilizando la opción Extractor de datos de PDF) para extraer los datos requeridos del archivo PDF. Guarde el perfil.
2.Ahora defina un segundo perfil de indexación que procesará el archivo de datos. En este caso, nuestro archivo de datos es un archivo TXT que contiene los nombres de los archivos PDF que se van a importar. El Extractor de datos de línea de texto tiene un delimitador ";", y el campo recibe el nombre "PDF file" (es solo u nombre arbitrario). 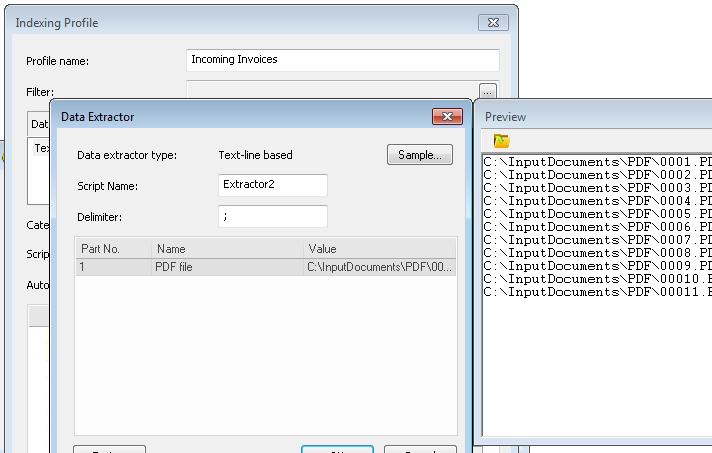
3.Ahora añada un script a este mismo perfil de indexación:
ExecuteProfile "PDF Import Test Profile", Extract("PDF file")
FilesToSave = Extract("PDF file")
Donde PDF Import Test Profile es el nombre del primer perfil creado (con el extractor de PDF) y PDF file es el nombre del campo definido en el Extractor de datos de línea de texto. Como puede verse en el script, este perfil llama primero al perfil del extractor de PDF y, a continuación, extrae y guarda los datos de cada archivo PDF procesado.
4.Tenga en cuenta que el campo Script del perfil de indexación aparecerá rojo, como si el script no fuera válido. Esto se puede ignorar, ya que el script se ejecutará correctamente. 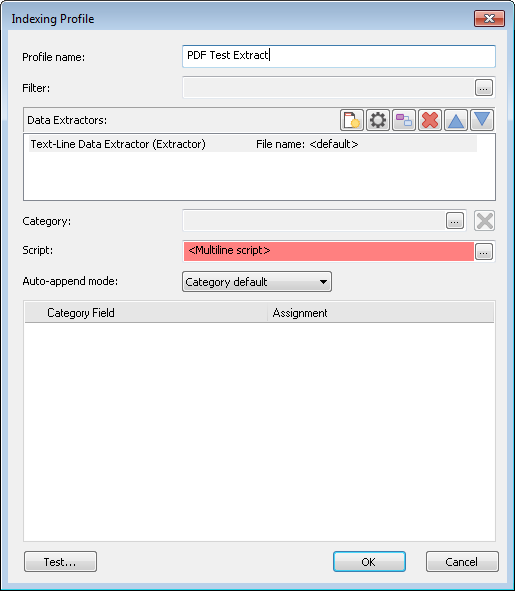
5.En Therefore™ Document Loader, seleccione el archivo de datos y elija el perfil con el Extractor de datos de línea de texto (el segundo que ha creado). Haga clic en Procesar para comenzar a importar los archivos. 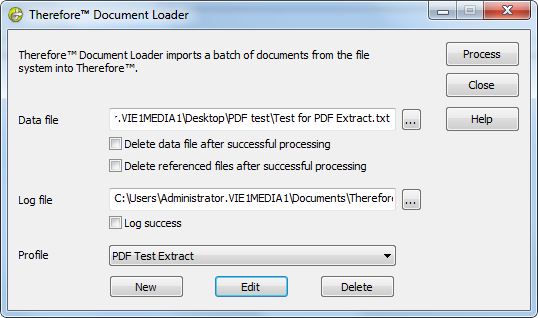
|
|
7.Puede comprobar el perfil haciendo clic en Prueba y seleccionando un archivo de datos de prueba. Haga clic en Aceptar para guardar el perfil de indexación.
8.Especifique la ubicación del Archivo de datos que desea importar y del Archivo de registro. A continuación, elija el perfil correspondiente. Consulte Referencias si desea más información sobre las opciones de las casillas. Haga clic en Procesar para comenzar a importar los archivos.
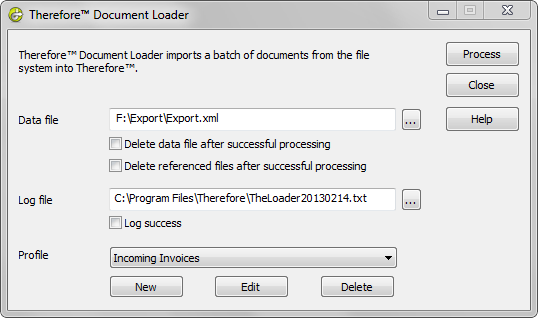
9.Después de importar todos los documentos, inicie Therefore™ Navigator y busque, recupere y vea algunos documentos para comprobar que todo está correcto.

