
|
Configuration of the SharePoint integration |
Scroll |
The configuration of the integration between Therefore™ and the Microsoft SharePoint Server takes place in the Therefore™ Solution Designer. The configuration allows multiple connections to on-premise Microsoft SharePoint systems as well as Microsoft SharePoint Online. For each connection, one or more profiles can be configured. Configurations for each tenant within multi-tenant systems are possible. The profiles are processed by the service Therefore™ Crawler for Microsoft Sharepoint.
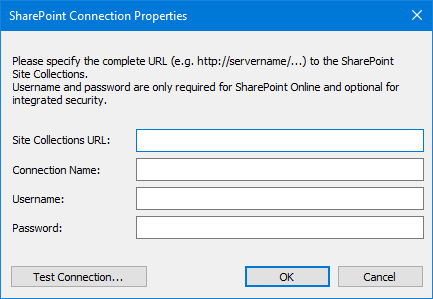
1.In the Therefore™ Solution Designer, navigate to the Integrations node. Right-click on the Microsoft SharePoint node and select New Connection.
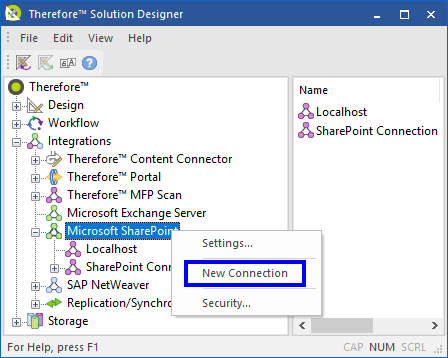
2. In the SharePoint Connection Properties dialog, specify the Site Collections URL and the Connection Name. If required, specify a Username and Password which is used to connect to Microsoft SharePoint. For connections to Microsoft SharePoint Online, Username and Password are mandatory.
|
The Connection Name can be chosen freely. |

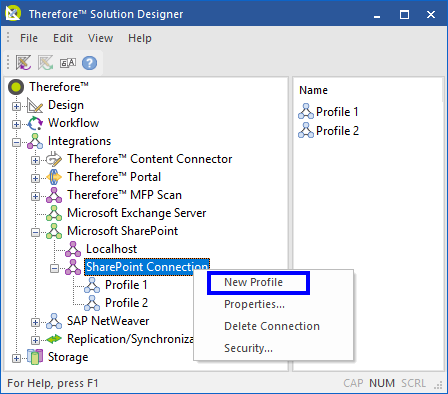
3. Open the context menu of the created SharePoint Connection node and select New Profile.
4. In the New Profile dialog, specify the required options in the Properties tab. To start processing the profile using the Crawler, Enable Profile must be selected.
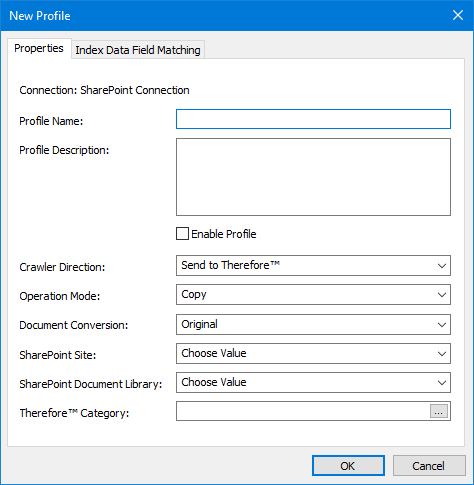
Please find a list of the various options that can be entered into the profile below.
Crawler Direction |
Description |
Send to Therefore™ |
The Crawler processes documents from SharePoint to Therefore™ |
Send To SharePoint |
The Crawler processes documents from Therefore™ to SharePoint |
Operation Mode |
Description |
Copy |
Documents will be duplicated from the source system to the target system. |
Move |
Documents will first be copied to the target system. After successful processing in the target system they will be deleted in the source system. |
Document Conversion |
Description |
Original |
During document processing the original type of the document will be preserved. |
JPEG |
During processing, the document will be converted from its original type into a JPEG image. |
Multipage PDF |
During processing, the document will be converted from its original type into a PDF file. |
Multipage TIFF |
During processing, the document will be converted from its original type into a TIFF image. |
Searchable PDF |
During processing, the document will be converted from its original type into a PDF file. Full-text information will be added to the PDF. |
Searchable PDF/A |
During processing, the document will be converted from its original type into a standard PDF/A file. |
SharePoint Site |
Description |
Sample: /Legal |
Specify the full path to the SharePoint site you wish to use. |
SharePoint Document Library |
Description |
Sample: Contracts |
Specify the SharePoint Document Library you wish to use. |
Therefore™ Category |
Description |
Sample: Contracts |
Specify the Therefore™ Category that you wish to use |
5. You need to specify how the metadata for the document is transferred from the source system to the target system. To do so, you need to specify which metadata field of the source system will be transferred to which field in the target system. This is called Index Data Field Matching and it is configured under the Index Data Field Matching tab of the New Profile dialog.
In the table, specify the matching pairs between SharePoint metadata fields and Therefore™ index data fields. The mandatory fields of the target system are automatically filled in the matching pair list and need to be properly associated with the field from the source system. If possible, the Crawler tries to convert between different data types of source and target fields (for example: source is a date and target is a text field).
By clicking Add Association, you can specify additional matching pairs between source and target system.
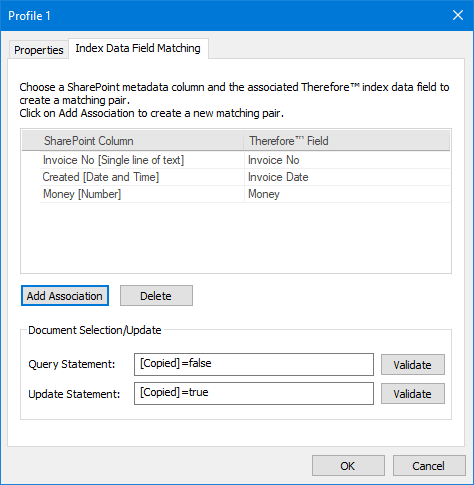
Document Selection/Update:
For the Query and Update statement, the field names must be enclosed in brackets.
The Query Statement is used to distinguish which documents are going to be processed by the crawler.
|
Multiple statements must be separated by semicolons. |
The Update Statement is used to update documents that have already been processed by the crawler.
|
•For example, the source system contains the field 'Copied' and the default value 'false'. After successful processing, the crawler will set this field to 'true'. •If the Operation Mode is set to copy, this statement is mandatory to prevent repeated processing of the same documents. |
