1.Before a profile can be created, a suitable category is required in Therefore™ to which the exported documents can be saved. Some thought and planning should be employed at this stage, since good indexing will improve how documents are handled later.
2.Start the Document Loader and under Profile click New.

|
You can also create and manage profiles in the Therefore™ Solution Designer.
|
3.The Profile dialog will open. Enter the Profile name. The next step is to set up a data extractor to get the index data from the data file. Click the Data extractor browse button: |
Choose XML Data Extractor.
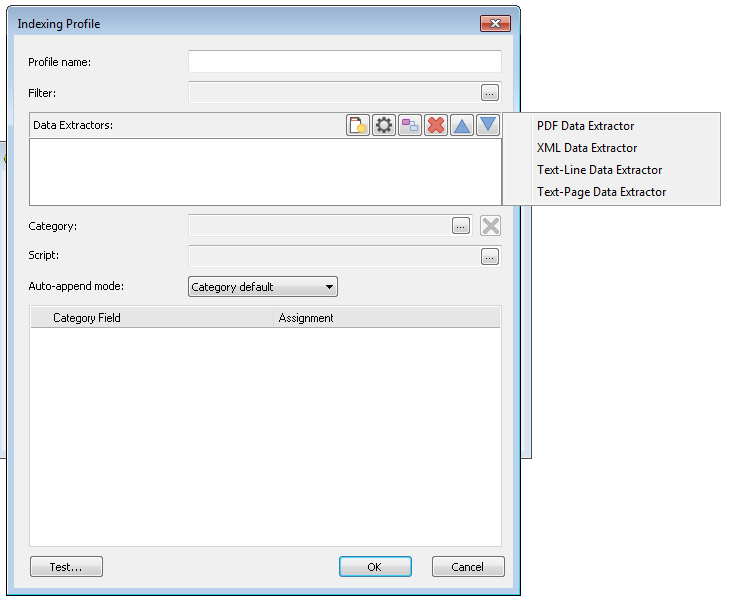
The Data Extractor dialog will open with a preview of the XML file. The XML tag defining the document needs to be defined now. In this case, document information is contained between the tags <Document> ...</Document>. In the left pane click on the tag name Document. By defining this one tag, the XML Data Extractor can extract all the document index field tags which we will use later to map the category field assignments.
|
Large XML files may take a long time to load and refresh. In such cases you could make a copy of the XML and delete all but one document. Then, use this new XML to create your profile, but use the original when you use the final profile.
|
Before clicking OK we also need to find out the tag that defines the reference files that make up the content of the document. In this example you can see a file "Invoice2009_002.pdf" and it is contained within the tags <FileName>Invoice2009_002.pdf</FileName>. Make a note of this tag for use in the next step of the profile design. In situations where the XML data file is the file that should be saved, this tag is not needed.
|
Choose Text-Line Data Extractor.
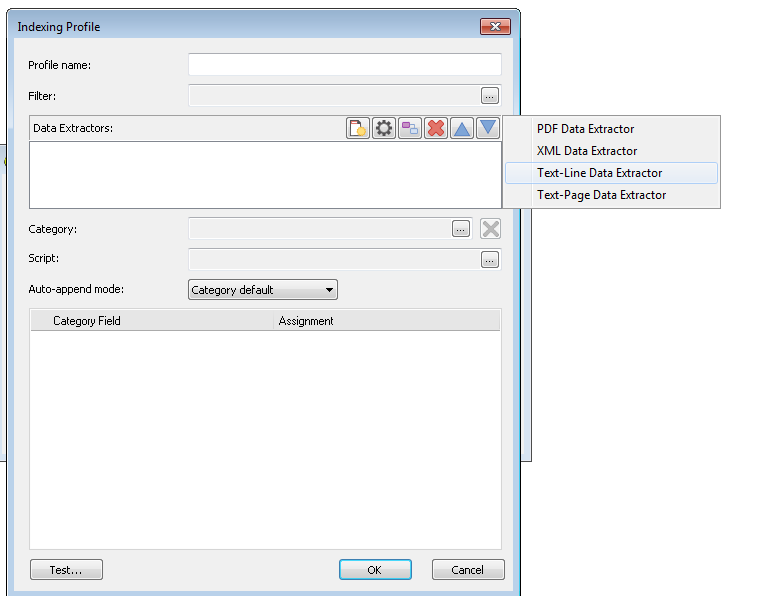
The Data Extractor dialog will open with a preview of the text file. Specify the Delimiter and the part numbers with values will be automatically listed. Enter names for the part numbers (index fields) that you would like to extract. In this example, Invoice No. will also be used as a document break and so we can set this to On change. You can also set the Quotes settings depending on the settings in the text file. Continue to define all other parts containing the index data that you require.
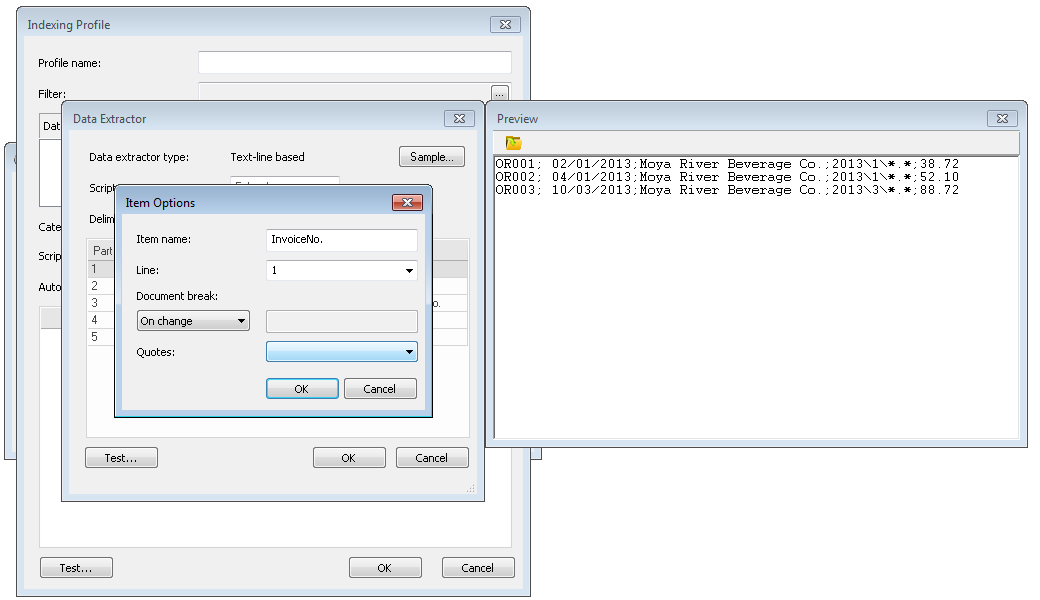
Once all the index fields have been defined, we need to also name the part that defines the reference files that make up the contents of the document. In this example it is the 4th part and we will call it FileName. Once done click OK to close the Data Extractor.
|
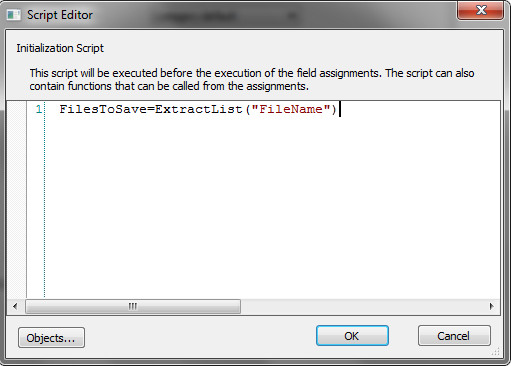
6.Next click the Script browse button and enter the script: FilesToSave = ExtractList("FileName") where FileName is the name of the tag from the previous step. It is important to use ExtractList and not just Extract because one document can contain multiple referenced files. Click OK to close the script dialog.
|
To make this step clear here are some wrong example scripts:
FilesToSave = Extract(“FileName”): will only extract the FIRST file in each document. If there is more than one file, it will not work.
FilesToSave = Extract(“FileNames”): will not import any files.
FilesToSave = ExtractList(“FileNames”): will not import any files.
The ONLY correct one for our example XML is FilesToSave = ExtractList("FileName")
|
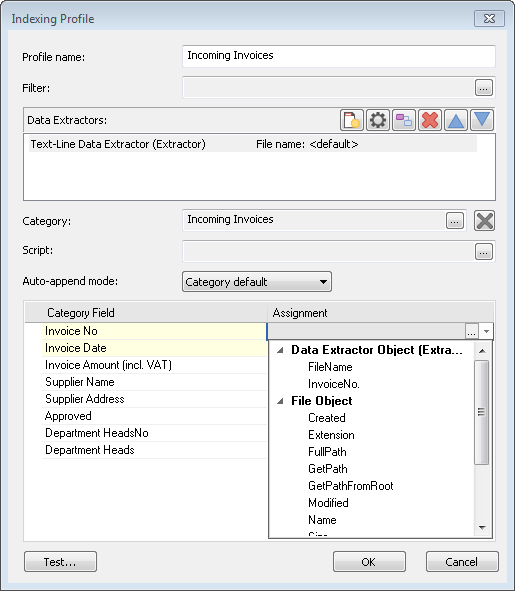
7.Select the Category where the documents should be saved. If auto-append has been configured in the category properties, then the Auto-append mode can be specified as different to the category default. Now the category's fields can be matched up. Click the drop-down list and choose the correct index field from the list of extracted index fields that we defined with the Data Extractor.
|
 Handling date formats Handling date formats
Where the date format on the documents to be imported differs from the date on the operating system where the Document Loader is running, the ToDate function can be used. For example if the documents have a date with format DD.MM.YYYY but the system uses another format then in the assignment above you could use: ToDate(Extract("Invoice Date"), "DD.MM.YYYY").
|
Line items
•Importing line items requires a script. For example for an XML data file with a table called "myTable" with two columns: "Text" and "Number".
<myTable>
<Text> Text1 </Text>
<Number> 1 </Number>
</myTable>
<myTable>
<Text> Text2 </Text>
<Number> 2 </Number>
</myTable>
In the Assignments, use: ExtractListTable("Text,"MyTable") and ExtractListTable("Number","MyTable")
|
Extracting information from the PDF contents
1.First define an indexing profile (using the option PDF Data Extractor) to extract the required data from the PDF file. Save the profile.
2.Now define a second indexing profile which will process the data file. In this case, our data file is a TXT file which contains the names of the PDF files to be imported. The Text-Line Data Extractor has a delimiter ";", and the field is given the name "PDF file" (this is just an arbitrary name).
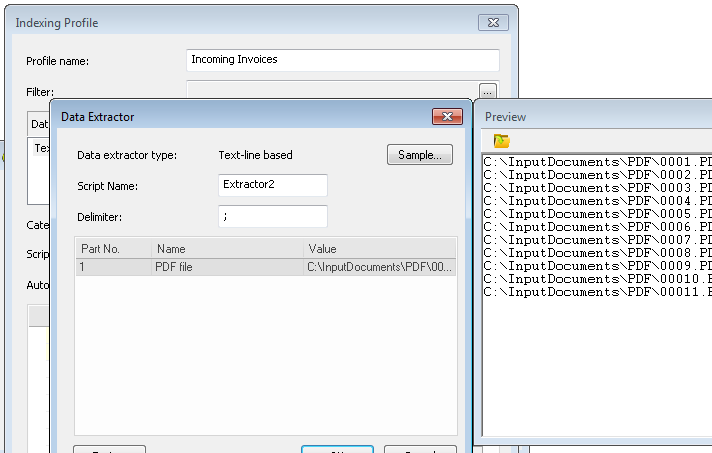
3.Now add a script to this same indexing profile:
ExecuteProfile "PDF Import Test Profile", Extract("PDF file")\
FilesToSave = Extract("PDF file")
Where PDF Import Test Profile is the name of the first profile created (with the PDF extractor) and PDF file is the name of the field defined in the Text-Line Data Extractor. As you can see from the script, this profile first calls the PDF extractor profile and then extracts and saves the data for each processed PDF file.
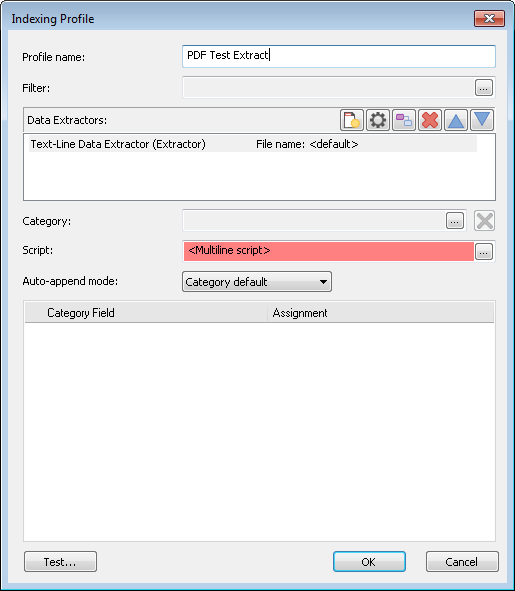
4.Note that the Script field in the indexing profile will appear red, as if the script is invalid. This can be ignored as the script will execute correctly.
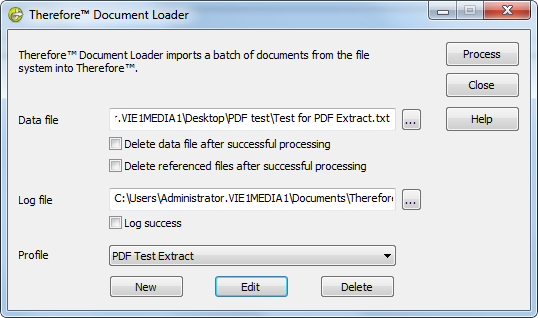
5.In the Therefore™ Document Loader, select your data file and choose the profile with the Text-Line Data Extractor (the second one you created). Click Process to start importing the files.
|
|
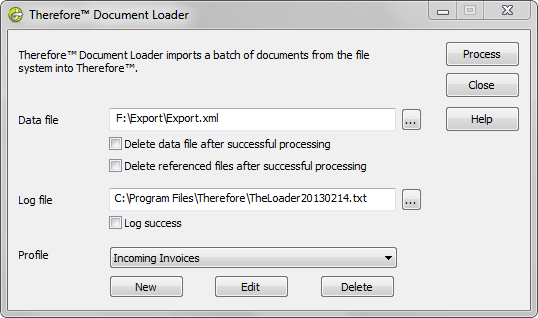
7.You can test the profile by clicking on Test and selecting a test data file. Click OK to save the indexing profile.
8.Specify the location of Data file for import, and the Log file. Then choose the relevant profile. See References for details on the check-box options. Click Process to start importing the files.
9.Once all documents have been imported, start Therefore™ Navigator and then search, retrieve and view some documents to ensure everything is OK.

