
|
File Profile |
Scroll |

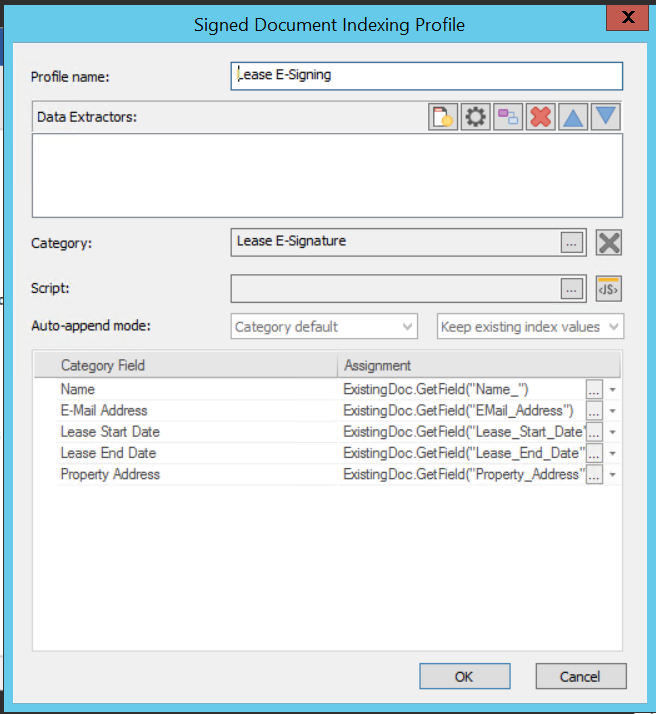
Profile name:
A name for the profile.
Filter:
A filter can be created to exclude or include files. For example:
File.Name<>"Template.pdf" will not process any files with name "Template.pdf".
File.Extension="pdf" will only process PDF files.
|
Wild cards are not supported here, but profiles used with the Therefore™ Content Connector can also contain a second filter that analyzes the files within an input folder. This job filter also supports wild cards. |

Data extractors can be used to extract data from various sources.
To create a new data extractor, click  .
.
To edit an exist extractor, click 
If more than one extractor is defined, the order of execution can be changed by moving them up or down in the list

To use the output of a proceeding data extractor click 
To remove a data extractor, click 
Data extractor types:
PDF Data Extractor:
Extracts data from a PDF or PDF/A file.
XML Data Extractor:
Extracts data from a XML file.
Text-Line Data Extractor:
Extracts text from a single line in a plain text file (containing ASCII characters, e.g. txt, csv, dat).
Text-Page Data Extractor:
Extracts text from a text file (containing ASCII characters, e.g. txt, csv, dat) containing multiple pages in a single document.
Barcode and OCR Data Extractor:
Extracts Barcode and OCR data from a document.
ZIP Data Extractor:
Processes ZIP files and extracts the data inside of them. The extracted files can be used in other data extractors.
Category:
The category where the files should be saved must be specified.
Script:
A script can be created which will be executed before the execution of the field assignments.
Auto-append mode:
The auto-append mode for documents saved with this profile can be defined by selecting an option from the drop-down menu.
Set the behavior regarding index data in the existing and resulting document by selecting an option from the second drop-down menu. The default option is 'Keep existing index values'.
'Keep existing index values': The index data of the resulting document is taken from the existing document. Fields which are empty in the existing document get their value from the new document.
'Overwrite index values': The index data of the resulting document is taken from the new document. Empty fields are filled from the existing document
Once a category has been chosen, a list of the index fields will be displayed. Clicking on the assignment down arrow will display a list of assignment variables. Clicking on the browse button opens a dialog where validation and error handling can be configured.
Test
The indexing profile can be tested using a sample file.
