 Come importare un batch di file in Therefore™ i cui dati indice si trovano in un file di dati
Come importare un batch di file in Therefore™ i cui dati indice si trovano in un file di dati
1.Per poter creare un profilo, è necessario che esista in Therefore™ una categoria idonea in cui salvare i documenti esportati. In questa fase è necessaria un'accurata pianificazione, in quanto una buona indicizzazione consentirà di agevolare sensibilmente la successiva gestione dei documenti.
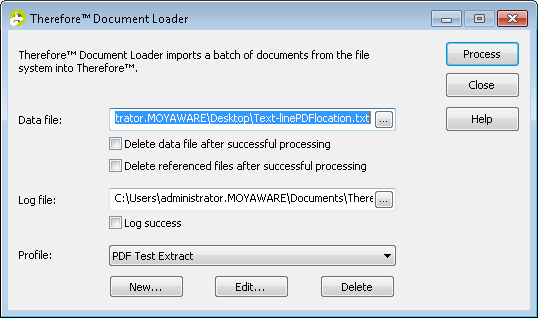
2.Avviare Document Loader e in corrispondenza di Profilo fare clic su Nuovo.

|
È anche possibile creare e gestire i profili direttamente in Therefore™ Solution Designer.
|
3.Viene visualizzata la finestra di dialogo Profilo. Immettere il nome profilo. Il passaggio successivo prevede l'impostazione dell'estrattore dati per estrarre i dati di indice dal data file. Fare clic sul pulsante Sfoglia nell'estrattore dati:
Scegliere Estrattore dati XML.
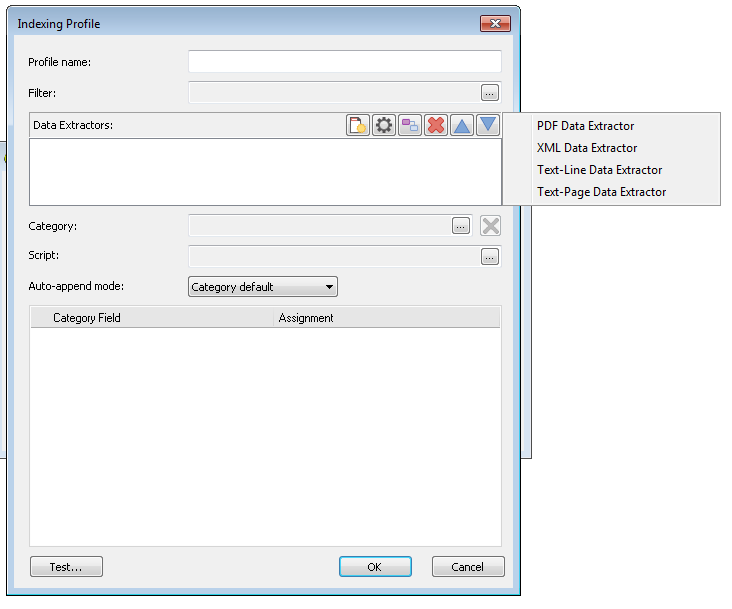
Viene visualizzata la finestra di dialogo dell'Estrattore dati che mostra un anteprima del file XML. Il tag XML che identifica il documento deve essere definito. In questo caso, le informazioni del documento sono contenute tra i tag <Document> ...</Document>. Nel riquadro sinistro fare clic sul tag con nome Document. La definizione di questo tag consente l'estrattore dati XML di estrarre tutti i tag dei campi di indice che verranno usati per mappare le assegnazioni dei campi della categoria.
|
È possibile che file XML voluminosi richiedano più tempo per caricarsi e aggiornarsi. In questo caso è possibile creare una copia del file XML e cancellare tutti i documenti tranne uno. Poi si può usare questo nuovo XML per creare il profilo, ma è necessario usare il file XML originale quando si usa il profilo finale.
|
Prima di fare click su OK è necessario riconoscere il tag che definisce i file di riferimento che fanno parte del contenuto del documento. In questo esempio si può vedere il file "Invoice2009_002.pdf" racchiuso tra i tag <FileName>Invoice2009_002.pdf</FileName>. Notare questo tag per usarlo nel prossimo passo della progettazione del profilo. Nel caso che il file di dati XML sia il file che deve essere salvato, non serve usare questo tag.
|
Scegliere Estrattore dati riga di testo.
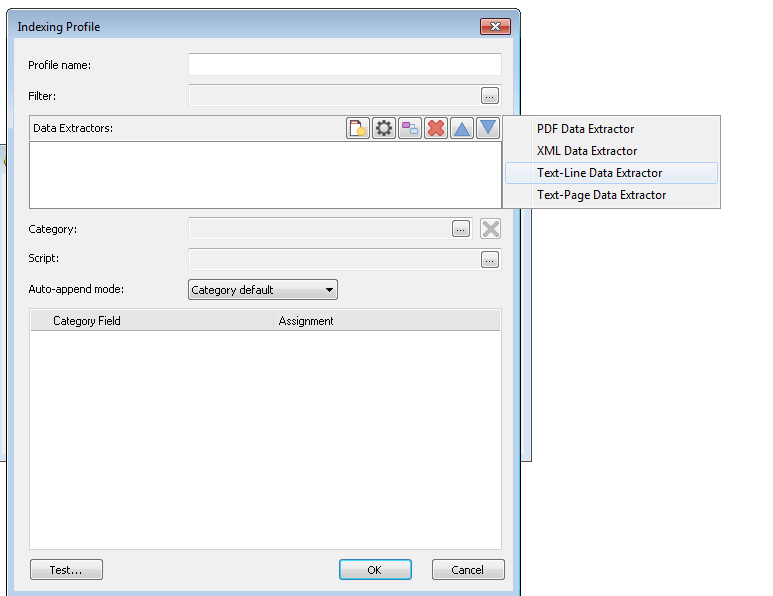
Viene visualizzata la finestra di dialogo dell'Estrattore dati che mostra un anteprima del file di testo. Specificare il delimitatore e i numeri di parte con i valori verranno elencati automaticamente. Immettere i nomi per i numeri di parte (campi indice) che si desidera estrarre. In questo esempio, Invoice No. verrà utilizzato anche come interruzione documento e quindi può essere impostato su Per modifica. È anche possibile definire le impostazioni Virgolette in base alle impostazioni del file di testo. Definire tutte le altre parti che contengono i dati di indice necessari.
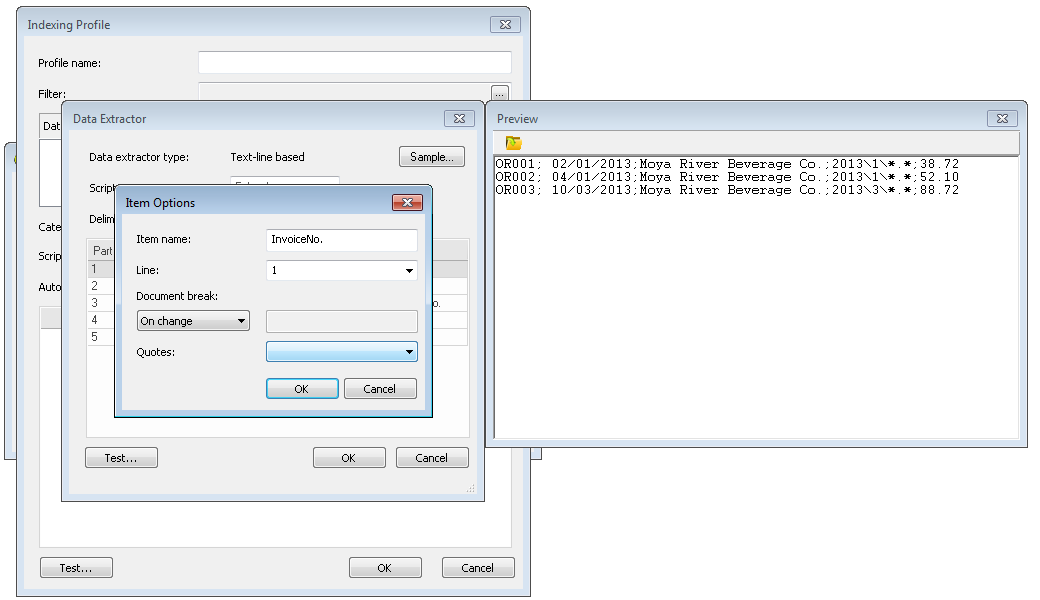
Una volta definiti i campi di indice, è necessario indicare la parteche definisce i file di riferimento che fanno parte del contenuto del documento. In questo caso si tratta della quarta parte, a cui viene assegnata il nome FileName. Al termine, fare clic su OK per chiudere l'estrattire dati.
|
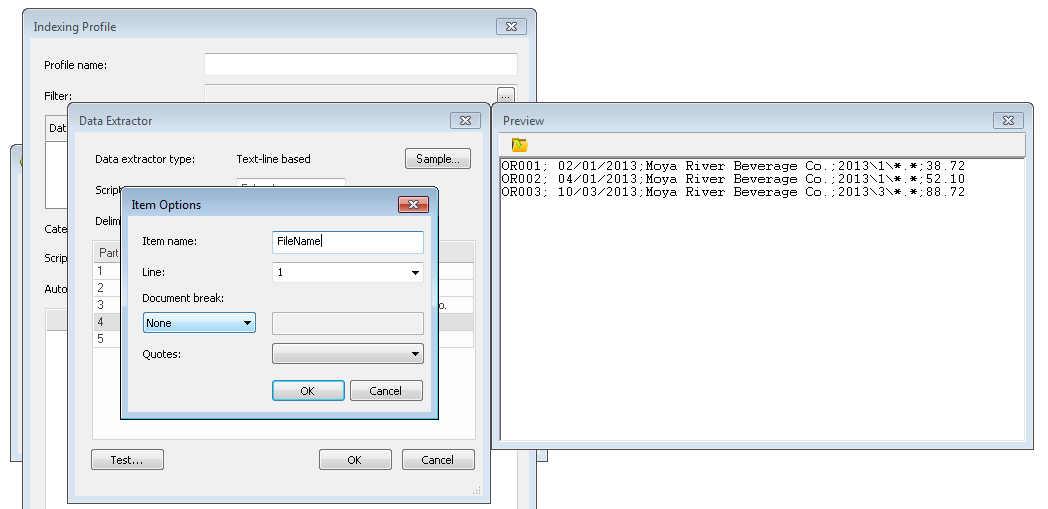
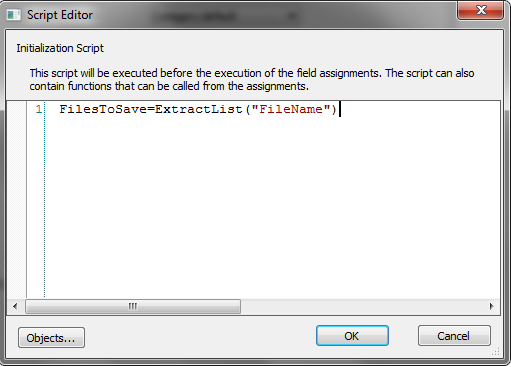
6.Poi fare clic sul pulsante Sfoglia Scripte inserire lo script: FilesToSave = ExtractList("FileName") dove FileName è il nome del tag del passaggio precedente. È importante usare ExtractList e non solo Extract perché lo stesso documento può contenere più file di riferimento. Fare clic su OK per chiudere il dialogo del script.
|
Per illustrare meglio questo passaggio, ecco degli esempi di script sbagliati:
FilesToSave = Extract(“FileName”): estrae solo il PRIMO file in ogni documento. Se c'è più di un file, non funzionerà.
FilesToSave = Extract(“FileNames”): non viene importato nessun file.
FilesToSave = ExtractList(“FileNames”): non importerà nessun file.
L'UNICO esempio corretto per il file XML di esempio è FilesToSave = ExtractList("FileName")
|
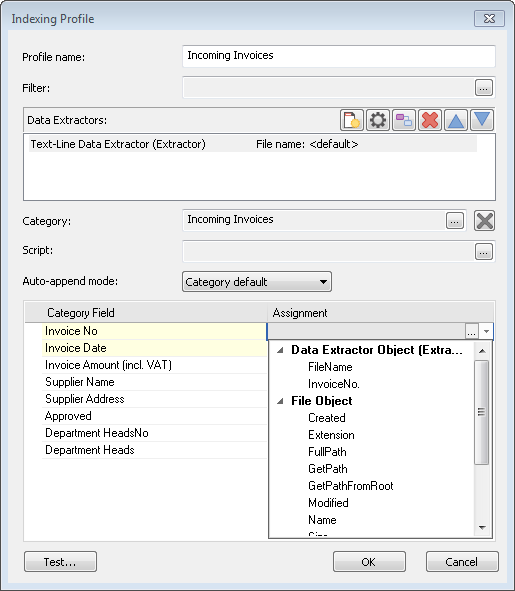
7.Selezionare la Categoria nella quale devono essere salvati i documenti. Se l'opzione di aggiunta automatica è stata configurata nelle proprietà di categoria, è possibile specificare la Modalità Aggiunta automatica in modo diverso rispetto alle impostazioni predefinite della categoria. A questo punto è possibile eseguire la corrispondenza dei campi della categoria. Fare clic sull'elenco a discesa e scegliere il campo indice corretto dalla lista dei campi indice che sono stati definiti con l'estrattore dati.
|
 Gestione dei formati data Gestione dei formati data
Quando il formato della data sui documenti da importare è diverso dalla data del sistema operativo sul quale è in esecuzione Document Loader, è possibile utilizzare la funzione ToDate. Ad esempio, se i documenti hanno una data nel formato DD.MM.YYYY ma il sistema usa un'altro formato, si potrebbe usare la funzione seguente: ToDate(Extract("Invoice Date"), "DD.MM.YYYY").
|
Elementi di riga
•L'importazione degli elementi di riga (voci) richiede uno script. Ad esempio, per un file di dati XML con una tabella denominata "myTable" con due colonne: "Text" e "Number".
<myTable>
<Text> Text1 </Text>
<Number> 1 </Number>
</myTable>
<myTable>
<Text> Text2 </Text>
<Number> 2 </Number>
</myTable>
Nella scheda Assegnazioni, utilizzare: ExtractListTable("Text,"MyTable") e ExtractListTable("Number","MyTable")
|
Estrazione di informazioni dal contenuto PDF
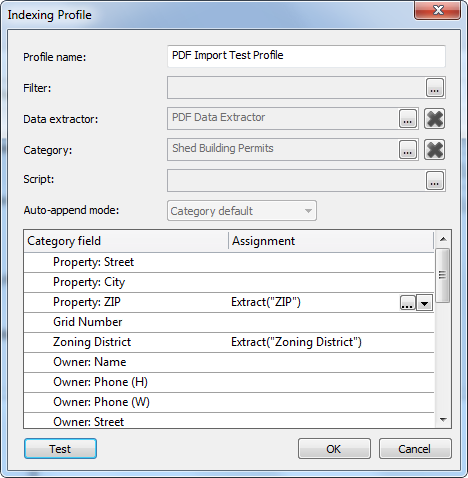
1.Innanzi tutto definire un profilo di indicizzazione (utilizzando l'opzione Estrattore dati PDF) per estrarre i dati necessari dal file PDF. Salvare il profilo.
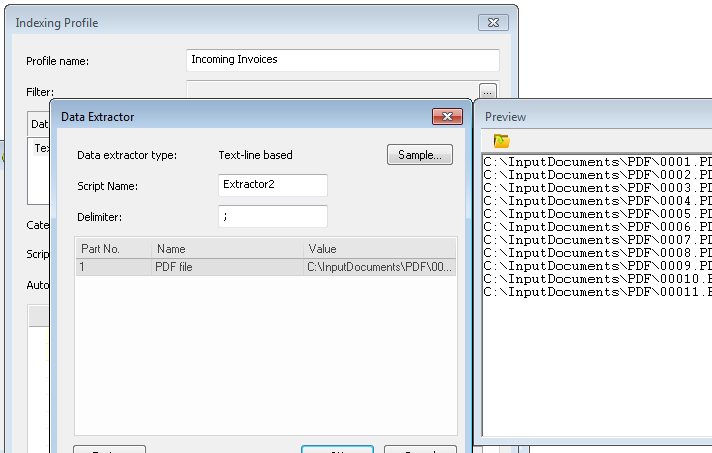
2.Quindi, definire un secondo profilo di indicizzazione che eseguirà l'elaborazione del file di dati. In questo caso, il file di dati è un file TXT che contiene i nomi dei file PDF da importare. L'Estrattore dati riga di testo contiene il delimitatore ";" e al campo è assegnato il nome "PDF file" (un nome a scelta).
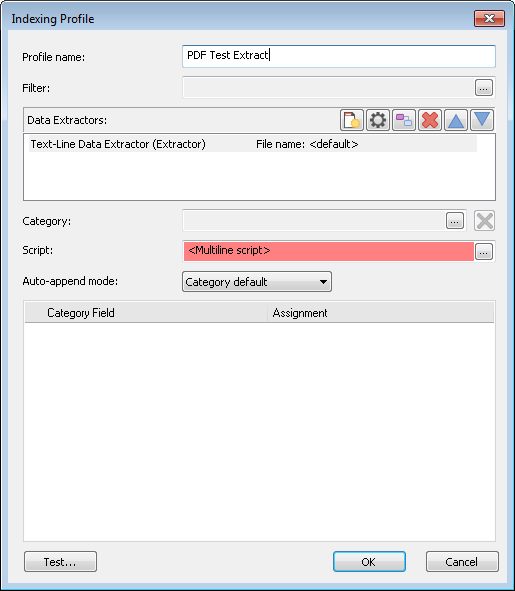
3.A questo punto, aggiungere uno script allo stesso profilo di indicizzazione:
ExecuteProfile "PDF Import Test Profile", Extract("PDF file")
FilesToSave = Extract("PDF file")
Dove PDF Import Test Profile è il nome del primo profilo creato (con l'estrattore PDF) e PDF file è il nome del campo definito nell'Estrattore dati riga di testo. Come si può vedere dallo script, questo profilo chiama inizialmente l'estrattore PDF e quindi estrae e salva i dati per ciascun file PDF elaborato.
4.Si noti che il campo Script nel profilo di indicizzazione apparirà in rosso, come se lo script non fosse valido. Si può ignorare questo fatto poiché lo script verrà eseguito correttamente.
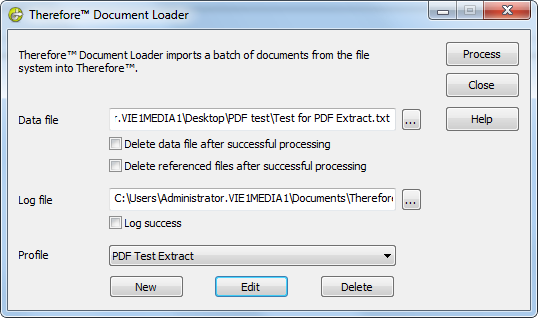
5.In Therefore™ Document Loader, selezionare il file di dati e scegliere il profilo con l'Estrattore dati riga di testo (il secondo che si è creato). Fare clic su Elabora per iniziare l'importazione dei file.
|
|
7.È possibile testare l'intero profilo facendo clic su Test e selezionando un data file di prova. Fare clic su OK per salvare il profilo di indicizzazione.
8.Specificare il percorso del File Dati da importare e del file di registro. Selezionare il profilo desiderato. Vedere Riferimenti per maggiori informazioni sulle opzioni delle caselle di controllo. Fare clic su Elabora per iniziare l'importazione dei file.
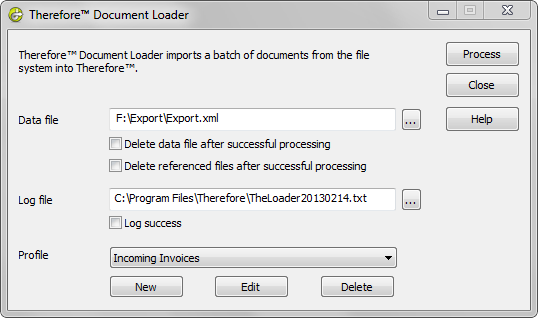
9.Una volta importati tutti i documenti, avviare Therefore™ Navigator, quindi cercare, recuperare e visualizzare alcuni di questi documenti per verificare che tutto sia andato a buon fine.

