 付属するデータ ファイルにインデックス データが含まれる Therefore™ にファイルのバッチをインポートするにはどうすればよいですか?
付属するデータ ファイルにインデックス データが含まれる Therefore™ にファイルのバッチをインポートするにはどうすればよいですか?
1.プロファイルを作成する前に、エクスポートしたドキュメントを保存する適切なカテゴリーが Therefore™ に必要です。インデックス作成を適切に行うことによって、後のドキュメント処理が向上するので、この段階で慎重な検討と計画を行っておくことが推奨されます。
2.Document Loader を起動して、プロファイルで新規作成をクリックします。
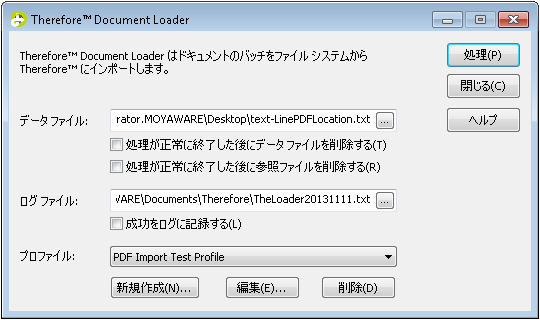

|
Therefore™ Solution Designer でプロファイルの作成と管理を行うこともできます。
|
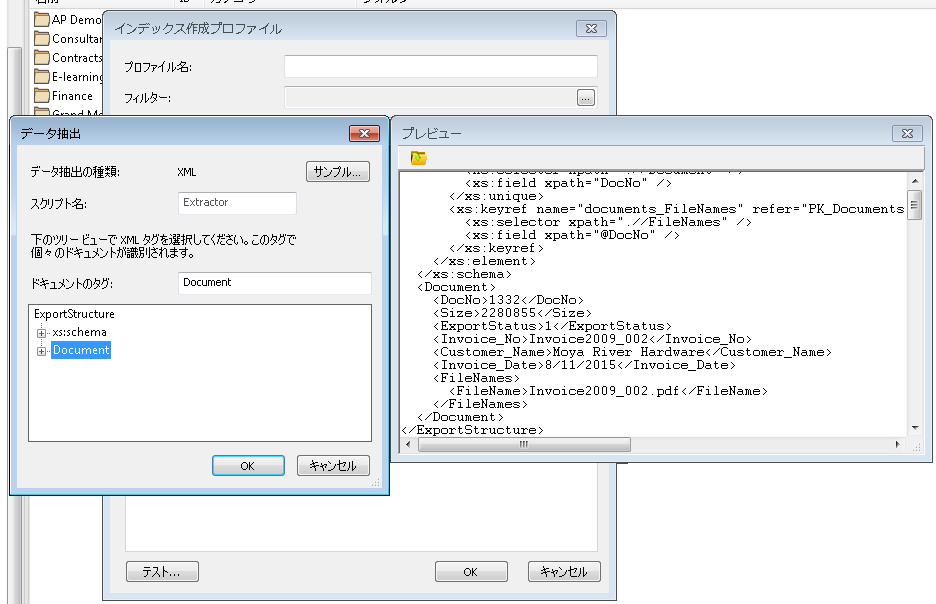
3.プロファイル ダイアログが開きます。プロファイル名を入力します。次に、データ抽出をセットアップして、データ ファイルからインデックス データを取得します。データ抽出先選択ボタンをクリックします。
XML データ抽出を選択します。
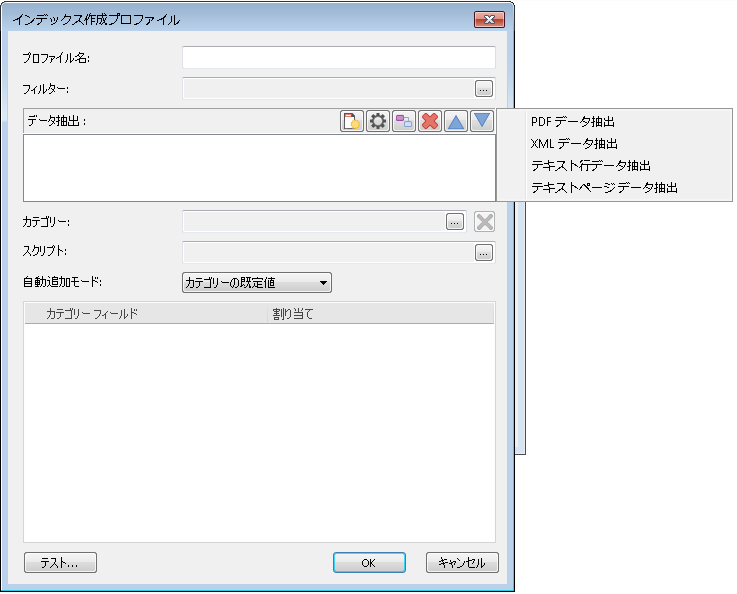
データ抽出ダイアログが開き、XML ファイルのプレビューが表示されます。ドキュメントを定義する XML タグを定義する必要があります。この場合、ドキュメント情報はタグの間(<Document> ...</Document>)に含まれています。左側のウィンドウで、Document というタグ名をクリックします。この 1 つのタグを定義することによって、後でカテゴリー フィールド割り当てを行うすべてのドキュメント インデックス フィールド タグを抽出できます。
|
サイズの大きい XML ファイルの場合、読み込みと更新に時間がかかることがあります。その場合、XML のコピーを作成して、1 つのドキュメント以外のすべてのドキュメントを削除できます。その後、この新しい XML を使用してプロファイルを作成します。しかし、最終的なプロファイルを作成するときには、オリジナルを使用します。
|
OK をクリックする前に、ドキュメントの本文を構築する参照ファイルを定義するタグを見つける必要があります。この例では、「Invoice2009_002.pdf」というファイルが <FileName>Invoice2009_002.pdf</FileName> タグ内に含まれています。このタグは、プロファイル設計の次のステップで使用します。XML データ ファイルが保存すべきファイルである場合、このタグは必要ありません。
|
テキスト行データ抽出を選択します。
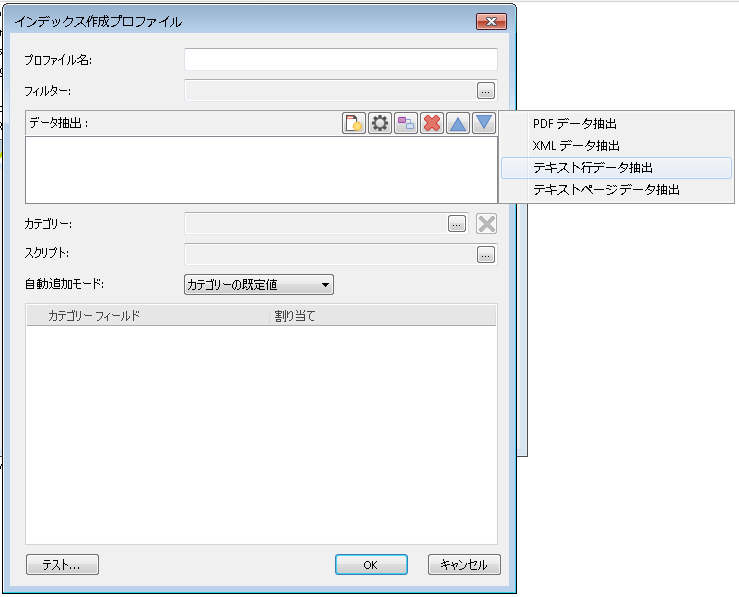
データ抽出ダイアログが開き、テキスト ファイルのプレビューが表示されます。区切り文字を指定すると、値を含む読み取り箇所の番号が自動的に表示されます。抽出する読み取り箇所の番号(インデックス フィールド)の名前を入力します。この例では、請求書番号もドキュメント区切りとして使用するので、これを変更時に設定します。テキスト ファイルの設定に応じて、引用符も設定できます。必要なインデックス データを含むその他の箇所を定義します。
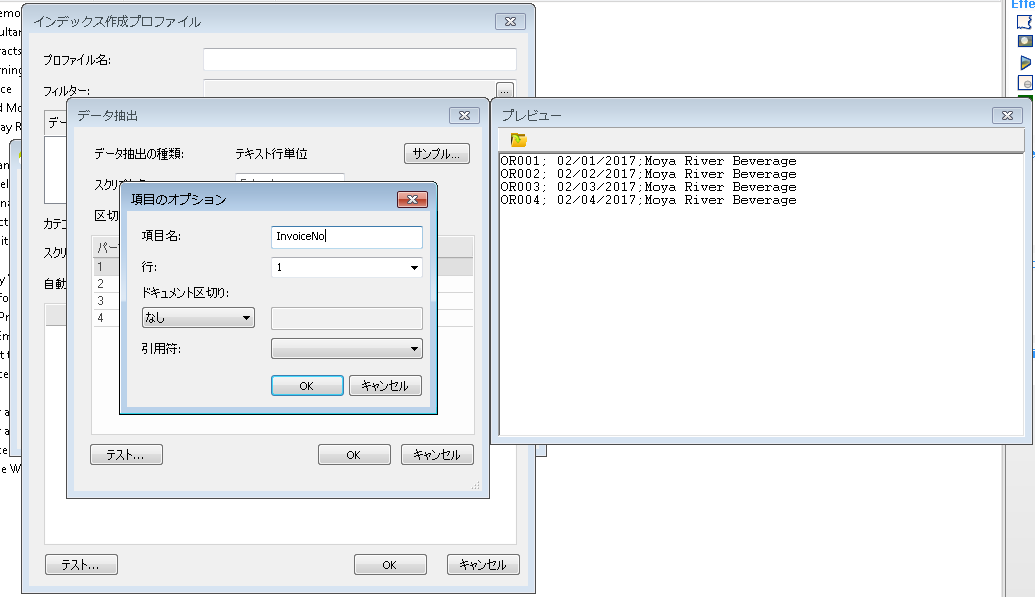
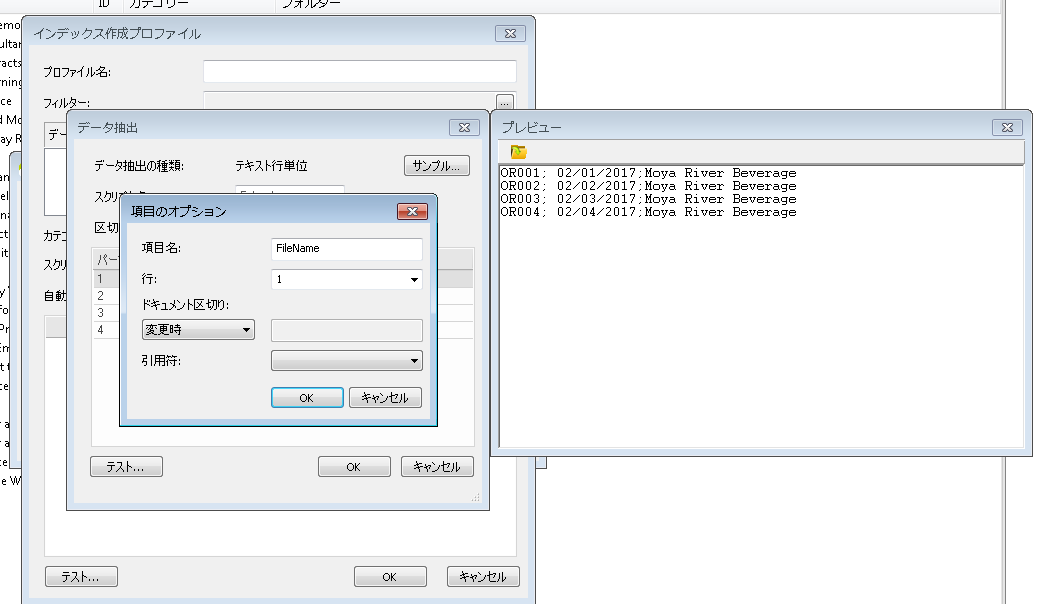
すべてのインデックス フィールドを定義したら、ドキュメントの本文を構成する参照ファイルを定義する箇所にも名前を付ける必要があります。この例では、4番目の箇所になります。ここでは、FileName という名前を付けます。完了したら、OK をクリックしてデータ抽出を閉じます。
|
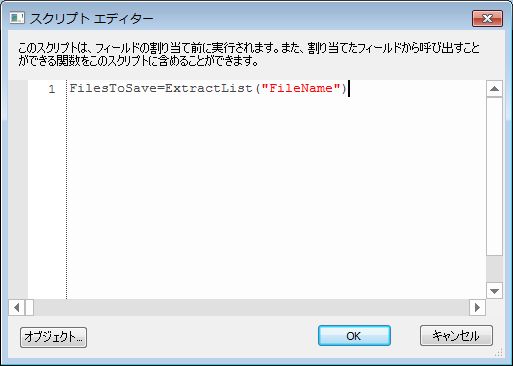
6.次に、スクリプト参照ボタンをクリックして、スクリプト FilesToSave = ExtractList("FileName") を入力します。ここで、FileName は、前の段階で指定したタグの名前です。1 つのドキュメントに複数の参照ファイルが含まれることがあるので、Extract だけではなく、ExtractList を使用することが重要です。OK をクリックして、スクリプト ダイアログを閉じます。
|
このステップの理解を深めるために、間違ったスクリプトの例を以下に示します。
FilesToSave = Extract(“FileName”):各ドキュメントの最初のファイルしか抽出されません。複数のファイルがある場合、このスクリプトは機能しません。
FilesToSave = Extract(“FileNames”):ファイルはインポートされません。
FilesToSave = ExtractList(“FileNames”):ファイルはインポートされません。
この例の XML ファイルで唯一正しいスクリプトは FilesToSave = ExtractList("FileName") です。
|
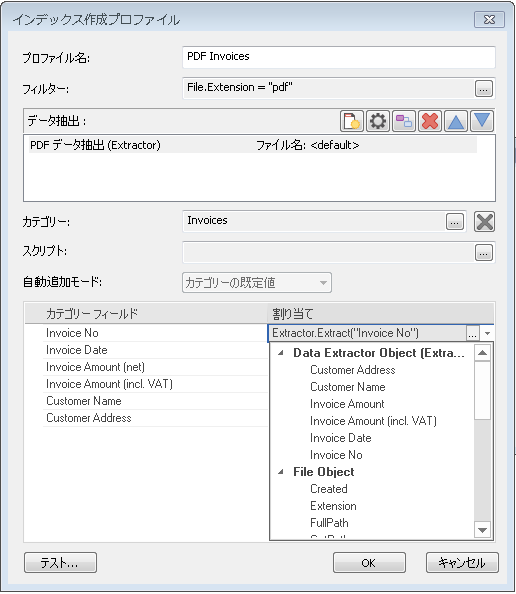
7.ドキュメントを保存するカテゴリーを選択します。カテゴリーのプロパティーで自動追加が設定されている場合、カテゴリーの既定値とは別に自動追加モードを指定できます。 これで、カテゴリーのフィールドを一致させることができます。ドロップダウン リストをクリックして、データ抽出で定義した抽出済みのインデックス フィールドのリストから正しいインデックス フィールドを選択します。
|
 日付形式の処理 日付形式の処理
インポートするドキュメントの日付形式と Document Loader が動作しているオペレーティング システムの日付と異なる場合、ToDate 関数を使用できます。例えば、ドキュメントの日付形式が DD.MM.YYYY で、システムで別の形式が使用されている場合、上記の割り当てで次のスクリプトを使用できます。ToDate(Extract("Invoice Date"), "DD.MM.YYYY")
|
行アイテム
•行アイテムのインポートにはスクリプトが必要です。例えば、「Text」と「Number」という 2 つの列がある「myTable」という名前のテーブルを含む XML データ ファイルの場合を考えて「Text」および「Number」という 2 つの列が含まれている場合を考えてみます。
<myTable>
<Text> Text1 </Text>
<Number> 1 </Number>
</myTable>
<myTable>
<Text> Text2 </Text>
<Number> 2 </Number>
</myTable>
割り当てでは、次のスクリプトを使用します。ExtractListTable("Text,"MyTable") および ExtractListTable("Number","MyTable")
|
PDF 本文からの情報の抽出
1.最初に、インデックス作成プロファイルを定義(PDF データ抽出オプションを使用)して、PDF ファイルから必要なデータを抽出します。プロファイルを保存します。 2.次に、データ ファイルを処理する 2 番目のインデックス作成プロファイルを定義します。この例のデータ ファイルは、インポートする PDF ファイルの名前を含む TXT ファイルです。テキスト行データ抽出には「;」 の区切り文字があり、フィールドには「PDF file」という名前が付けられています(これは便宜的な名前)。 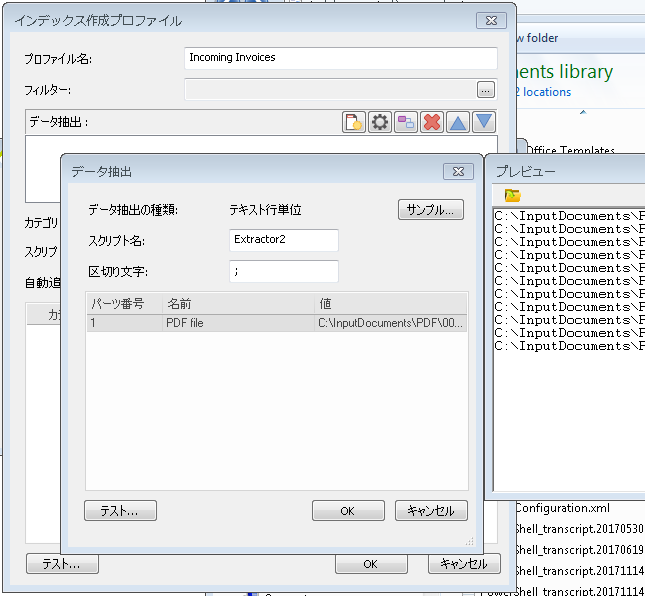
3.次に、この同じインデックス作成プロファイルにスクリプトを追加します。
ExecuteProfile "PDF Import Test Profile", Extract("PDF file")\
FilesToSave = Extract("PDF file")
ここで、PDF Import Test Profile は(PDF の抽出で)作成する 1 番目のプロファイルの名前です。PDF file は、テキスト行データ抽出で定義されたフィールドの名前です。スクリプトから分かるように、このプロファイルでは、最初に PDF の抽出プロファイルが呼び出された後、処理された各 PDF ファイルのデータが抽出および保存されます。
4.インデックス作成プロファイルのスクリプトフィールドが赤く表示されることに注意してください(スクリプトが無効であることを示すように見える)。スクリプトは正しく実行されるので、無視してください。 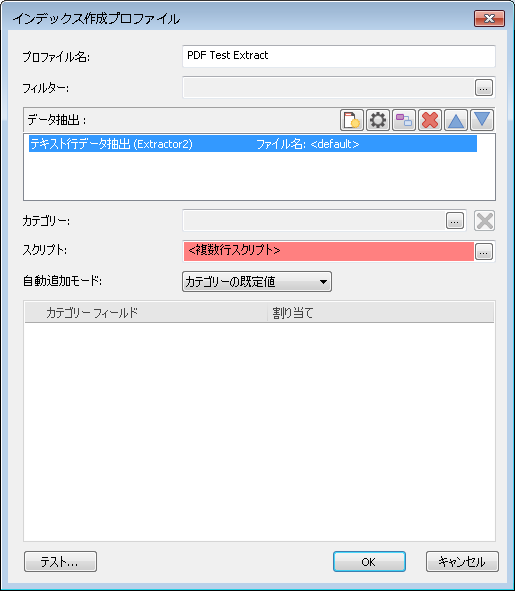
5.Therefore™ Document Loader でデータ ファイルを選択して、テキスト行データ抽出を使用してプロファイル(作成した 2 番目のプロファイル)を選択します。プロセスをクリックして、ファイルのインポートを開始します。 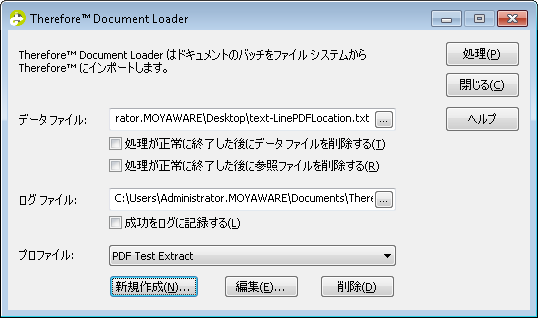
|
|
7.プロファイルをテストするには、テストをクリックして、テスト データ ファイルを選択します。OK をクリックして、インデックス作成プロファイルを保存します。
8.インポートするデータ ファイルとログ ファイルの場所を指定します。次に、関連するプロファイルを選択します。チェックボックス オプションの詳細については、リファレンスを参照してください。プロセスをクリックして、ファイルのインポートを開始します。
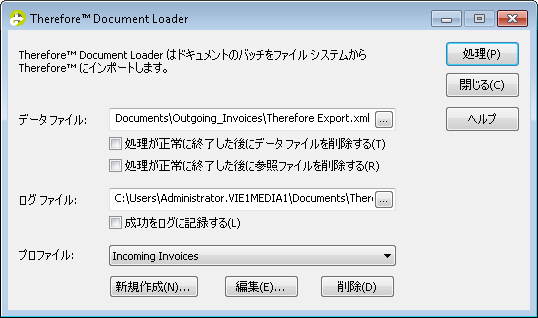
9.すべてのドキュメントがインポートされた後、Therefore™ Navigator を起動して、いくつかのドキュメントを検索、抽出、および表示して問題がないことを確認します。
|
Therefore™ Document Loader は、自動モードでも実行できます。
|

