
|
ファイルのプロファイル |
Scroll |

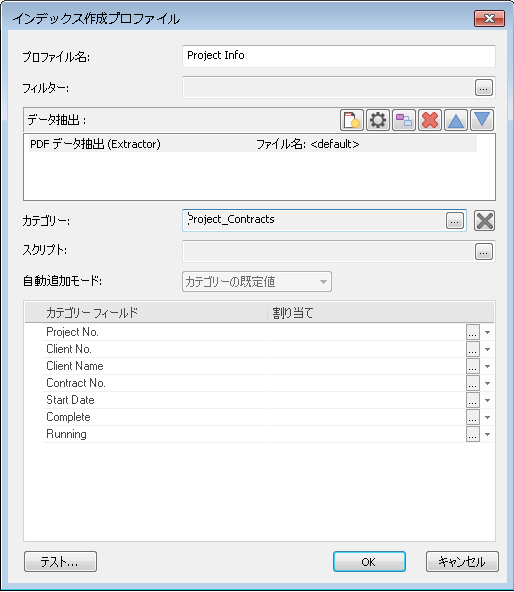
プロファイル名:
プロファイルの名前です。
フィルター:
ファイルを除外する、あるいは含めるフィルターを作成できます。例:
File.Name<>"Template.pdf" では、"Template.pdf" の名前を持つファイルが処理されません。
File.Extension="pdf" では、PDF ファイルのみが処理されます。
|
ワイルド カードはサポートされていませんが、Therefore™ Content Connectorで使用されるプロファイルには入力フォルダー内でファイルを解析する二次フィルターを設定できます。このジョブ フィルターもワイルド カードをサポートします。 |

データ抽出は、様々なソースからデータを抽出するために使用できます。
新しいデータ抽出を作成するには、 をクリックします。
をクリックします。
既存のデータ抽出の編集を行うには、 をクリックします。
をクリックします。
複数のデータ抽出が定義されている場合には、リスト内で上下
 に移動することによって実行順序を変更できます。
に移動することによって実行順序を変更できます。
使用しているデータ抽出の出力を使用するには、 をクリックします。
をクリックします。
データ抽出を削除するには、 をクリックします。
をクリックします。
データ抽出の種類:
PDF データ抽出
PDF または PDF/A ファイルからデータを抽出します。
XML データ抽出
XML ファイルからデータを抽出します。
テキスト行データ抽出
プレーン テキスト ファイル(ASCII文字を含む、たとえば txt、csv、dat ファイル)内の単一行からテキストを抽出します。
テキストページ データ抽出
単一ドキュメント内に複数ページを含むテキスト ファイル(ASCII文字を含む、たとえば txt、csv、dat ファイル)からテキストを抽出します。
バーコードと OCR のデータ抽出
ドキュメントからバーコードと OCR データを抽出します。
カテゴリー:
ファイルを保存するカテゴリーを指定する必要があります。
スクリプト:
フィールド割り当ての前に実行するスクリプトを作成することができます。
自動追加モード:
このプロファイルで保存されたドキュメントに対する自動追加モードを定義できます。
カテゴリーが選択されている場合、インデックス フィールドのリストが表示されます。割り当ての下向き矢印をクリックすると、割り当て変数のリストが表示されます。参照ボタンをクリックするとダイアログが開きます。このダイアログで、検証とエラー処理が設定可能です。
テスト
インデックス作成プロファイルをサンプル ファイルでテストできます。
