 So importieren Sie einen Dateistapel in Therefore™, wenn die Indexdaten in einer beiliegenden Datendatei enthalten sind:
So importieren Sie einen Dateistapel in Therefore™, wenn die Indexdaten in einer beiliegenden Datendatei enthalten sind:
1.Bevor Sie ein Profil erstellen können, muss in Therefore™ eine geeignete Kategorie existieren, in der die exportierten Dokumente gespeichert werden können. In dieser Phase ist ein gewisses Maß an Überlegung und Planung erforderlich, denn eine gute Indexierung führt später zu einer besseren Verarbeitung der Dokumente.
2.Starten Sie den Document Loader und klicken Sie unter Profil auf Neu.
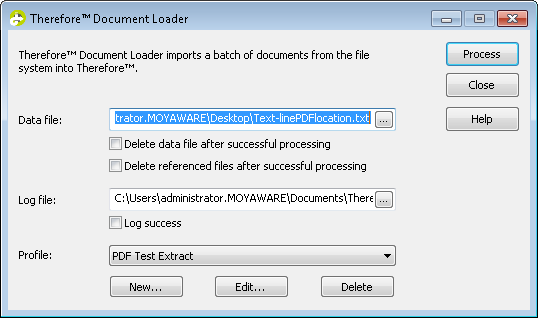

|
Sie können Profile auch in Therefore™ Solution Designer erstellen und verwalten.
|
3.Das Dialogfeld "Profil" wird geöffnet. Geben Sie den Profilnamen ein. Im nächsten Schritt richten Sie einen Datenextraktor ein, um die Indexdaten aus der Datendatei zu extrahieren. Klicken Sie auf die Schaltfläche "Datenextraktor":
Wählen Sie XML-Datenextraktor.
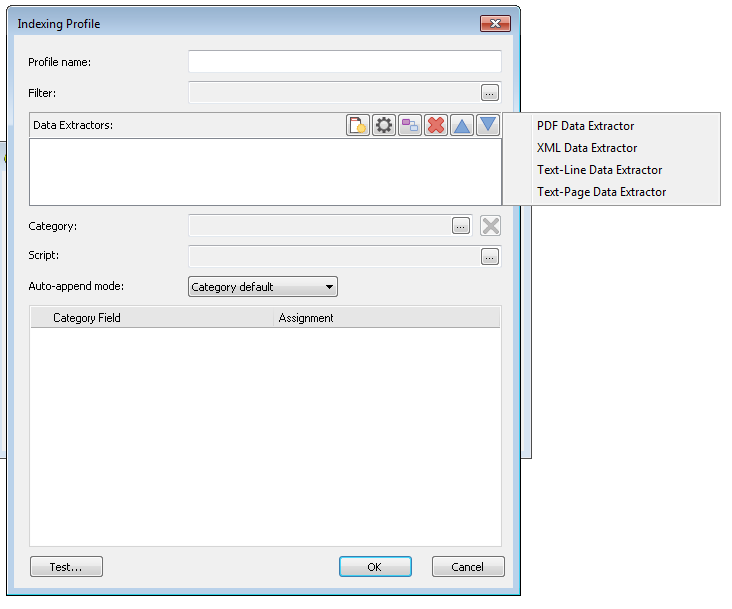
Das Dialogfeld Datenextraktor wird mit einer Vorschau der XML-Datei geöffnet. Jetzt müssen Sie den XML-Tag definieren, der das Dokument definiert. In diesem Fall befinden sich die Dokumentinformationen zwischen den Tags <Document> ...</Document>. Klicken Sie im linken Fensterbereich auf den Tag-Namen Document. Durch Definieren dieses spezifischen Tags kann der XML-Datenextraktor alle Indexfeld-Tags des Dokuments extrahieren, die wir später zum Zuordnen der Kategoriefeldzuweisungen verwenden.
|
Das Laden und Aktualisieren großer XML-Dateien kann viel Zeit in Anspruch nehmen. In diesem Fall können Sie eine Kopie der XML erstellen und alle Dokumente bis auf eines löschen. Erstellen Sie Ihr Profil dann mit dieser neuen XML. Verwenden Sie beim Verwenden des endgültigen Profils jedoch die Original-XML.
|
Bevor Sie auf OK klicken, müssen Sie den Tag finden, der die Referenzdateien definiert, die den Inhalt des Dokuments bilden. In diesem Beispiel sehen Sie die Datei "Invoice2009_002.pdf" in den Tags <FileName>Invoice2009_002.pdf</FileName>. Notieren Sie sich diesen Tag, denn er wird im nächsten Schritt des Profildesigns verwendet. Wenn es sich bei der XML-Datendatei um die Datei handelt, die gespeichert werden soll, wird dieser Tag nicht gebraucht.
|
Wählen Sie Text-Zeile-Datenextraktor.
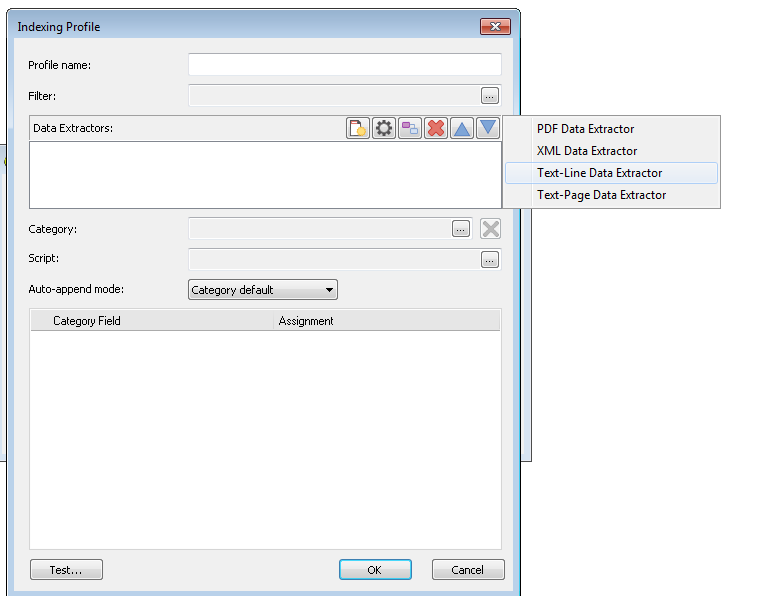
Das Dialogfeld Datenextraktor wird mit einer Vorschau der Textdatei geöffnet. Geben Sie das Trennzeichen an. Daraufhin werden die Teilenummern mit Werten automatisch aufgelistet. Geben Sie Namen für die Teilenummern (Indexfelder) ein, die extrahiert werden sollen. In diesem Beispiel wird "Rechnungsnummer". auch als Dokumentumbruch verwendet, sodass sie auf Bei Änderung gesetzt werden kann. Darüber hinaus können Sie die Einstellungen für Anführungszeichen entsprechend den Einstellungen in der Textdatei einrichten. Definieren Sie auch alle anderen Teile, die von Ihnen benötigte Indexdaten enthalten.
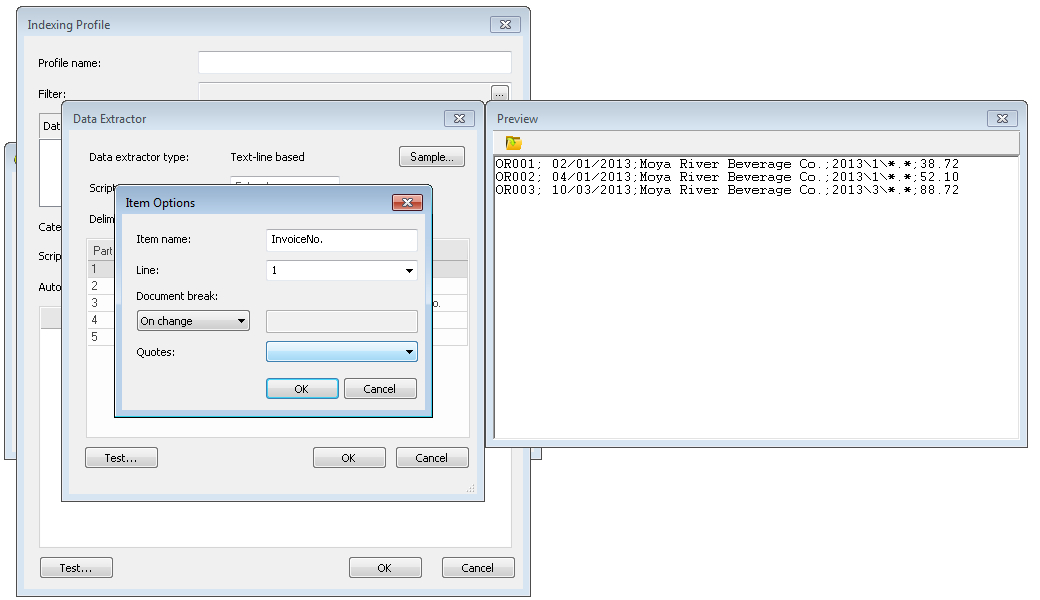
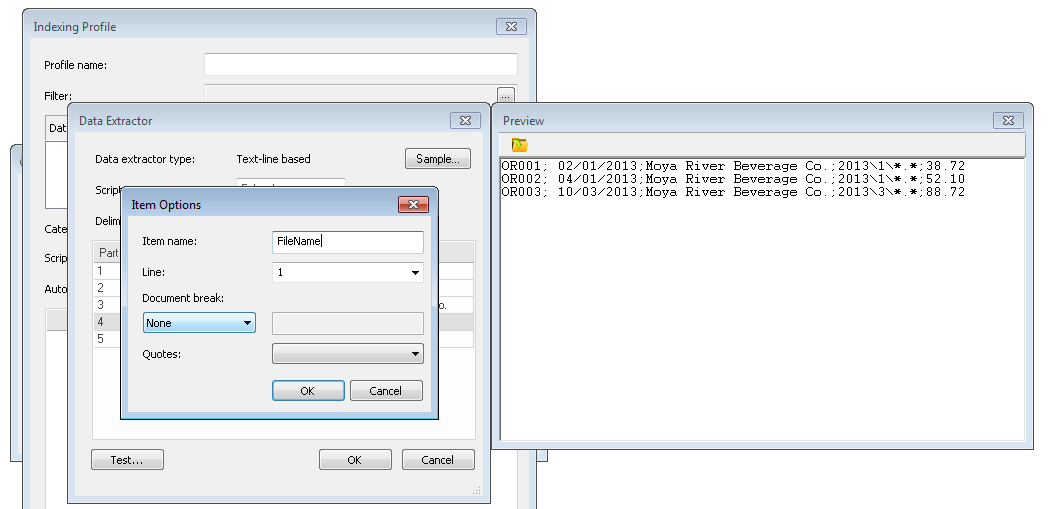
Nachdem alle Indexfelder definiert wurden, müssen wir außerdem den Teil benennen, der die Referenzdateien enthält, die den Inhalt des Dokuments bilden. In diesem Fall ist dies der vierte Teil, den wir FileName nennen. Klicken Sie abschließend auf OK, um den Datenextraktor zu beenden.
|
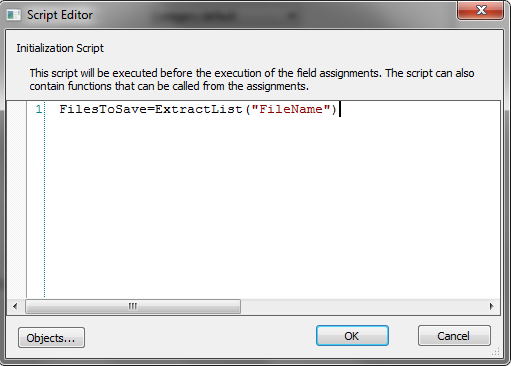
6.Klicken Sie als Nächstes auf die Navigationsschaltfläche Skript und geben Sie das folgende Skript ein: FilesToSave = ExtractList("FileName") wobei FileName der Name des Tags aus dem vorhergehenden Schritt ist. Sie müssen ExtractList verwenden und nicht einfach Extract, da ein Dokument mehrere Referenzdateien enthalten kann. Klicken Sie auf OK, um das Skriptdialogfeld zu schließen.
|
Zur Verdeutlichung dieses Schritts zeigen wir Ihnen hier einige falsche Beispielskripte:
FilesToSave = Extract(“FileName”): extrahiert nur die ERSTE Datei in jedem Dokument. Bei mehreren Dateien funktioniert dieses Skript nicht.
FilesToSave = Extract(“FileNames”): importiert keine Dateien.
FilesToSave = ExtractList(“FileNames”): importiert keine Dateien.
Das EINZIGE korrekte Skript für unser Beispiel ist FilesToSave = ExtractList("FileName")
|
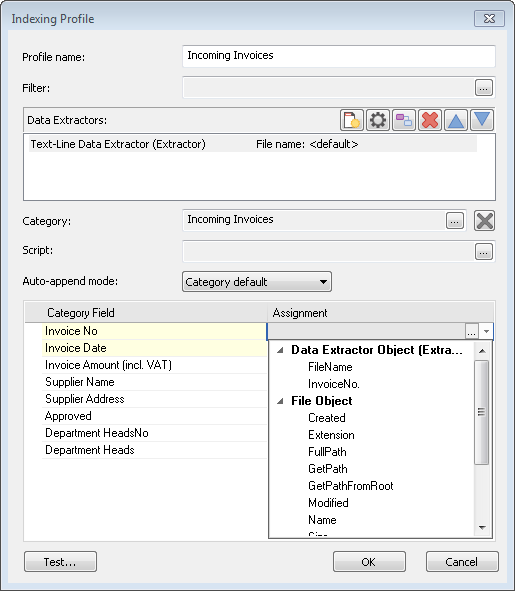
7.Wählen Sie die Kategorie aus, in der die Dokumente gespeichert werden sollen. Wenn "Auto-Anhängen" in den Kategorieeigenschaften aktiviert wurde, können Sie für den Auto-Anhängen-Modus einen anderen Wert als den Kategoriestandard einrichten. Im nächsten Schritt werden die Felder der Kategorie zugeordnet. Klicken Sie auf die Dropdownliste und wählen Sie das richtige Indexfeld aus der Liste extrahierter Indexfelder aus, die wir mit dem Datenextraktor definiert haben.
|
 Datumsformate verarbeiten Datumsformate verarbeiten
Wenn das Datumsformat in den zu importierenden Dokumenten vom Datumsformat auf dem Computer abweicht, auf dem der Document Loader ausgeführt wird, können Sie die Funktion ToDate verwenden. Wenn in den Dokumenten beispielsweise das Format DD.MM.YYYY verwendet wird, das System aber ein anderes Datumsformat verwendet, dann könnten Sie den folgenden Ausdruck in der Zuweisung oben verwenden: ToDate(Extract("Invoice Date"), "DD.MM.YYYY").
|
Zeilenelemente
•Für den Import von Zeilenelementen ist ein Skript erforderlich. Nehmen wir als Beispiel eine XML-Datendatei, welche die Tabelle "myTable" mit zwei Spalten enthält: "Text" und "Number".
<myTable>
<Text> Text1 </Text>
<Number> 1 </Number>
</myTable>
<myTable>
<Text> Text2 </Text>
<Number> 2 </Number>
</myTable>
Verwenden Sie Folgendes in den Zuweisungen: ExtractListTable("Text,"MyTable") and ExtractListTable("Number","MyTable")
|
Informationen aus dem PDF-Inhalt extrahieren
1.Definieren Sie als Erstes ein Indexierungsprofil (über die Option PDF-Datenextraktor), um die gewünschten Daten aus der PDF-Datei zu extrahieren. Speichern Sie das Profil. Definieren Sie dann ein zweites Indexierungsprofil für die Verarbeitung der Datendatei. In unserem Beispiel handelt es sich dabei um eine TXT-Datei mit den Namen der PDF-Dateien, die importiert werden sollen. Der Text-Zeile-Datenextraktor verwendet das Trennzeichen ";" und das Feld erhält den Namen "PDF file" (ein beliebiger Name).
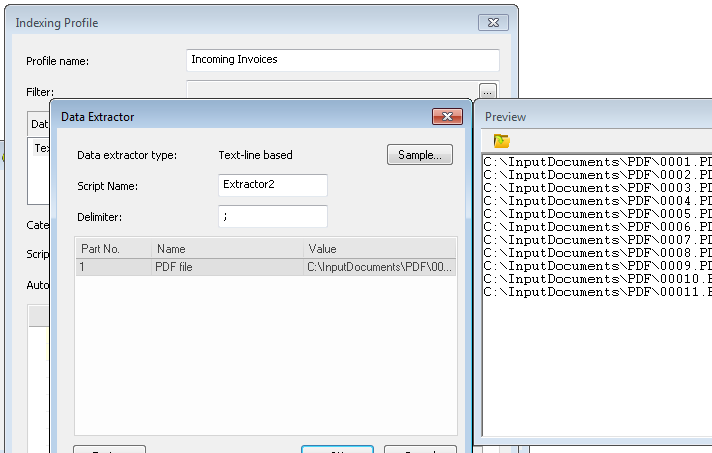
2.Fügen Sie jetzt das folgende Skript zum Indexierungsprofil hinzu:
ExecuteProfile "PDF Import Test Profile", Extract("PDF file")
FilesToSave = Extract("PDF file")
Dabei ist PDF Import Test Profile der Name des zuerst erstellten Profils (mit dem PDF-Extraktor) und PDF file ist der Name des im Text-Zeile-Datenextraktor definierten Feldes. Wie Sie im Skript sehen, ruft dieses Profil zuerst das PDF-Extraktorprofil auf und es extrahiert und speichert dann die Daten für jede verarbeitete PDF-Datei.
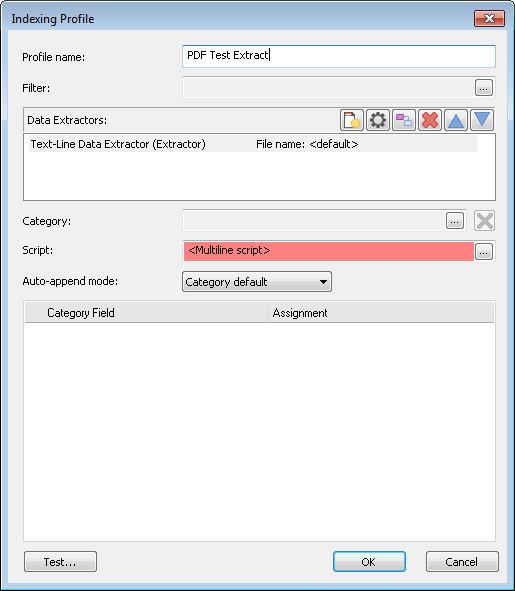
3.Beachten Sie dabei, dass das Feld Skript im Indexierungsprofil rot markiert erscheint, als ob das Skript ungültig wäre. Sie können dies ignorieren, da das Skript korrekt ausgeführt wird.
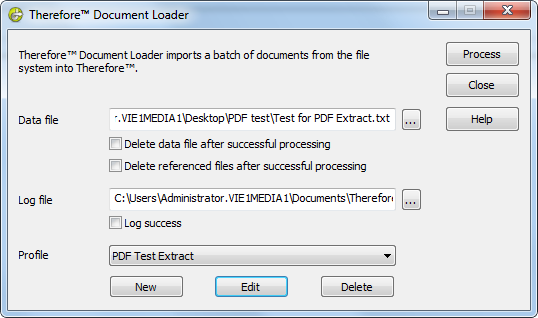
4.Wählen Sie in Therefore™ Document Loader Ihre Datendatei aus und wählen Sie das Profil mit dem Text-Zeile-Datenextraktor aus (das zweite Profil, das Sie erstellt haben). Klicken Sie auf Verarbeiten, um den Importvorgang zu starten.
|
|
7.Sie können das Profil testen, indem Sie auf Test klicken und eine Testdatendatei auswählen. Klicken Sie auf OK, um das Indexierungsprofil zu speichern.
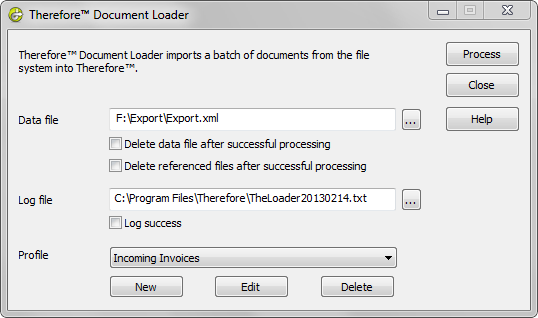
8.Geben Sie den Speicherort der zu importierenden Datendatei und die Protokolldatei an. Wählen Sie dann das relevante Profil aus. Einzelheiten zu den Kontrollkästchen-Optionen finden Sie unter Referenzen. Klicken Sie auf Verarbeiten, um den Importvorgang zu starten.
9.Starten Sie nach dem Import aller Dokumente den Therefore™ Navigator und prüfen Sie, ob alles in Ordnung ist, indem Sie nach einigen Dokumenten suchen, diese abrufen und anzeigen.

