Comment importer un lot de fichiers dans Therefore™ si les données d'index sont mémorisées dans un fichier de données associé ?
1.Pour créer un profil, une catégorie appropriée, dans laquelle les documents exportés peuvent être mémorisés, doit être définie dans Therefore™. Mettez au point une indexation adaptée, car elle a une incidence majeure sur la gestion future des documents.
2.Démarrez Document Loader et cliquez sur Nouveau sous Profil.
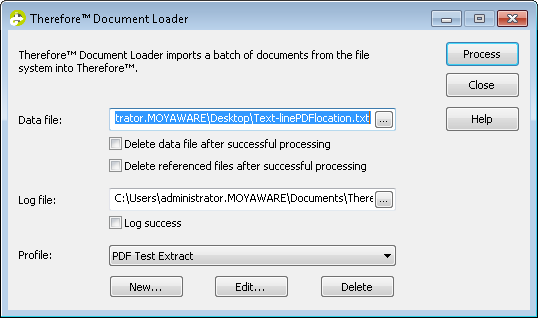

|
Vous pouvez également créer et gérer des profils dans Therefore™ Solution Designer.
|
3.La boîte de dialogue Profil s'affiche. Entrez le nom du profil. L'étape suivante consiste à définir un extracteur de données afin de récupérer les données d'index du fichier de données. Cliquez sur le bouton Parcourir associé au champ Extracteur de données :
Sélectionnez Extracteur de données XML.
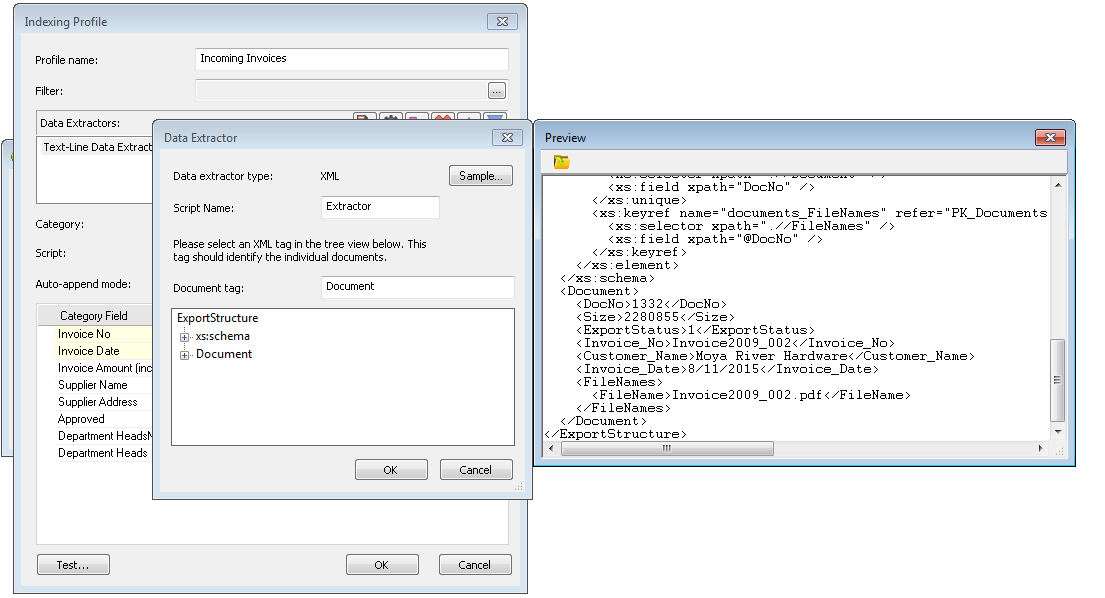
La boîte de dialogue Extracteur de données qui s'affiche contient un aperçu du fichier XML. Vous devez à présent spécifier le marqueur XML qui définit le document. Dans ce cas de figure, les informations relatives aux documents figurent entre les marqueurs <Document> ...</Document>. Dans le volet gauche, cliquez sur le nom de marqueur Document. Si vous définissez cet unique marqueur, l'extracteur de données XML peut extraire tous les marqueurs de champs d'index de document que nous utiliserons ultérieurement pour mapper les affectations de champs de catégorie.
|
Le chargement et l'actualisation des fichiers XML volumineux risquent d'être longs. Si tel est le cas, vous pourriez faire une copie du fichier XML et supprimer tous les documents, sauf un. Utilisez ensuite ce nouveau fichier XML pour créer le profil, mais utilisez le fichier d'origine avec le profil définitif.
|
Avant de cliquer sur OK, nous devons également identifier le marqueur qui définit les fichiers de référence composant le document. L'exemple illustré se rapporte au fichier « Invoice2009_002.pdf », indiqué entre les marqueurs <FileName>Invoice2009_002.pdf</FileName>. Prenez note de ce marqueur, car vous l'utiliserez à l'étape suivante de la création du profil. Lorsque le fichier de données XML correspond au fichier à mémoriser, ce marqueur est inutile.
|
Sélectionnez Extracteur de données de ligne de texte.
La boîte de dialogue Extracteur de données qui s'affiche contient un aperçu du fichier texte. Renseignez le champ Séparateur. Les numéros de section contenant des valeurs sont automatiquement recensés. Entrez le nom des numéros de section (champs d'index) à extraire. Dans cet exemple, « Invoice No. » (Numéro de facture) est également utilisé à titre de séparateur de document. Nous pouvons donc activer l'option En cas de modification. Selon les paramètres du fichier texte, vous pouvez aussi définir les paramètres Guillemets. Continuez à définir tout autre élément contenant les données d'index requises.
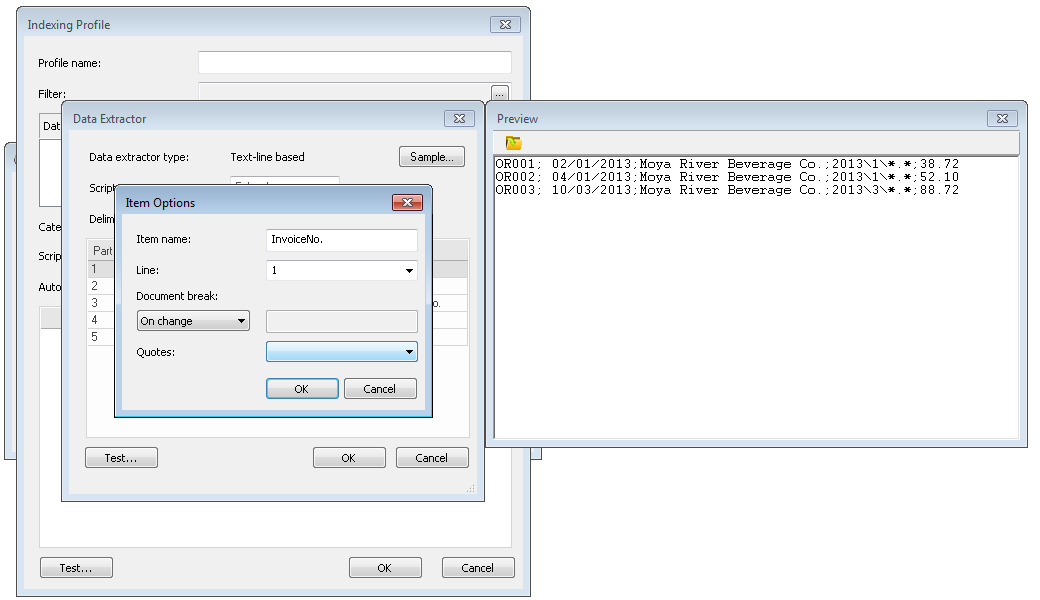
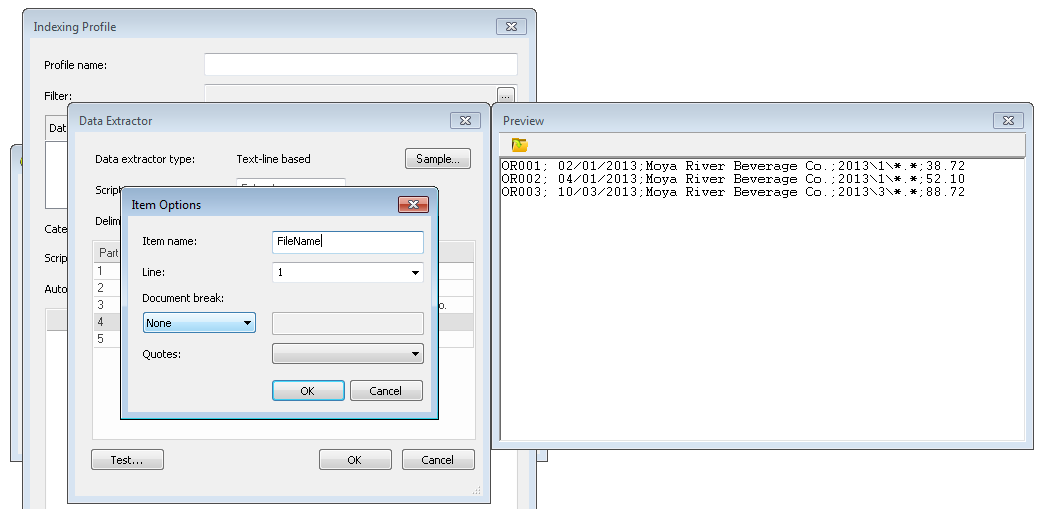
Une fois tous les champs d'index définis, nous devons également assigner un nom à l'élément qui définit les fichiers de référence composant le document. Dans l'exemple illustré, il s'agit du 4e élément, que nous allons appeler FileName. Cliquez ensuite sur OK pour fermer la boîte de dialogue Extracteur de données.
|
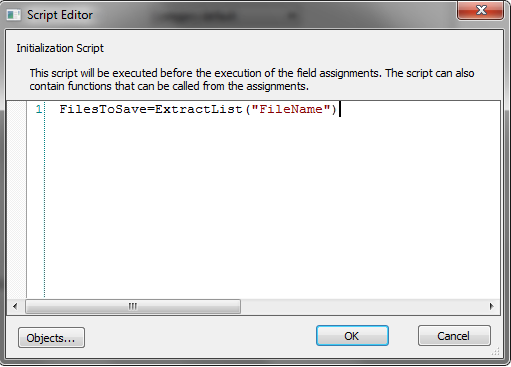
6.Cliquez ensuite sur le bouton Parcourir en regard de Script et entrez le script suivant : FilesToSave = ExtractList("FileName") où FileName correspond au nom du marqueur identifié à l'étape précédente. Il est important d'utiliser ExtractList plutôt que Extract uniquement, car un même document peut contenir plusieurs fichiers référencés. Cliquez sur OK pour fermer la boîte de dialogue contenant le script.
|
Afin d'expliquer cette étape, voici quelques exemples de scripts incorrects :
FilesToSave = Extract(“FileName”) : extrait uniquement le PREMIER fichier de chaque document. Si les documents contiennent plusieurs fichiers, l'opération échoue.
FilesToSave = Extract(“FileNames”): n'importe aucun fichier.
FilesToSave = ExtractList(“FileNames”): n'importe aucun fichier.
L'UNIQUE script adapté à l'exemple de fichier XML est FilesToSave = ExtractList("FileName")
|
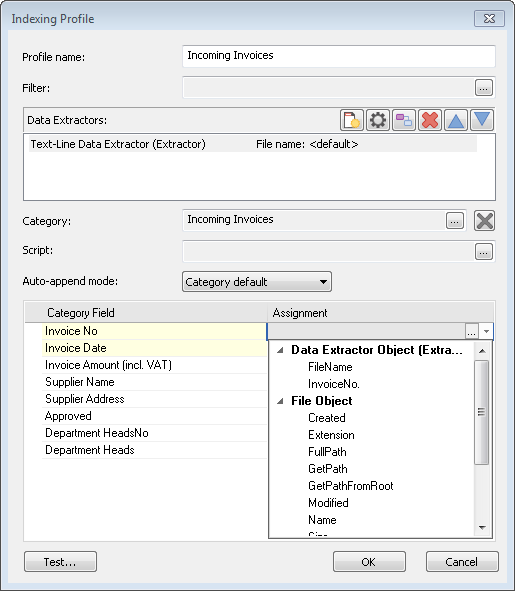
7.Sélectionnez la catégorie dans laquelle seront mémorisés les documents. Si vous avez configuré l'ajout automatique dans les propriétés de catégorie, vous pouvez spécifier dans Mode d'ajout automatique une option autre que Catégorie par défaut. Vous pouvez maintenant mettre en correspondance les champs de la catégorie. Cliquez dans la liste déroulante et sélectionnez le champ d'index correct dans la liste de champs d'index extraits définis dans la boîte de dialogue Extracteur de données.
|
 Gestion des formats de date Gestion des formats de date
Lorsque le format de date des documents à importer n'est pas identique au format de date utilisé par le système d'exploitation de la machine sur laquelle s'exécute Document Loader, vous pouvez utiliser la fonction ToDate. Si, par exemple, le format de date en vigueur dans les documents correspond à JJ.MM.AAAA, mais que le système utilise un autre format, vous pouvez entrer le texte suivant dans le champ Affectation ci-dessus : ToDate(Extract("Invoice Date"), "DD.MM.YYYY").
|
Lignes
•L'importation de lignes requiert un script. Prenons l'exemple d'un fichier de données XML contenant un tableau appelé « myTable » à deux colonnes : « Text » et « Number ».
<myTable>
<Text> Text1 </Text>
<Number> 1 </Number>
</myTable>
<myTable>
<Text> Text2 </Text>
<Number> 2 </Number>
</myTable>
Dans Affectation, utilisez : ExtractListTable("Text,"MyTable") et ExtractListTable("Number","MyTable")
|
Extraction d'informations du contenu d'un fichier PDF
1.Commencez par définir un profil d'indexation (à l'aide de l'option Extracteur de données PDF) pour extraire les données requises du fichier PDF. Mémorisez le profil. Définissez à présent un second profil d'indexation qui traitera le fichier de données. Dans ce cas de figure, notre fichier de données est un fichier TXT qui contient le nom des fichiers PDF à importer. L'extracteur de données de ligne de texte utilise le séparateur « ; » et le nom « fichier PDF » (nom quelconque) est assigné au champ.
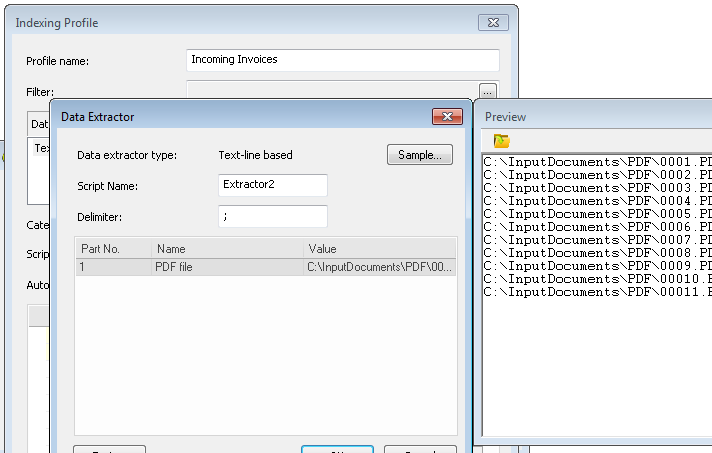
2.Ajoutez maintenant un script à ce profil d'indexation :
ExecuteProfile "PDF Import Test Profile", Extract("PDF file")
FilesToSave = Extract("PDF file")
Où PDF Import Test Profile est le nom du premier profil créé (à l'aide de l'extracteur PDF) et PDF file est le nom du champ défini dans l'extracteur de données de ligne de texte. Comme vous pouvez l'observer dans le script, ce profil commence par appeler le profil de l'extracteur PDF, puis extrait et mémorise les données de chaque fichier PDF traité.
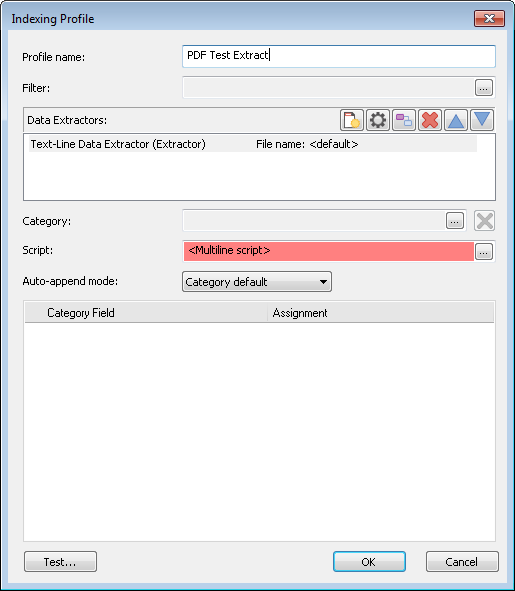
3.Notez que le champ Script du profil d'indexation s'affiche en rouge, puisque le script n'est pas valide. N'en tenez pas compte, car le script s'exécutera correctement.
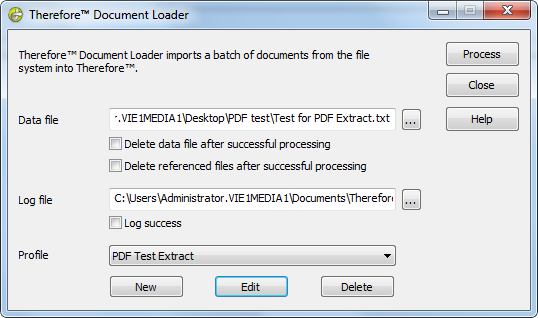
4.Dans Therefore™ Document Loader, sélectionnez le fichier de données et choisissez le profil contenant l'extracteur de données de ligne de texte (c'est-à-dire le second profil créé). Cliquez sur Processus pour démarrer l'importation des fichiers.
|
|
7.Pour tester le profil, cliquez sur Test et sélectionnez un fichier de données test. Cliquez sur OK pour mémoriser le profil d'indexation.
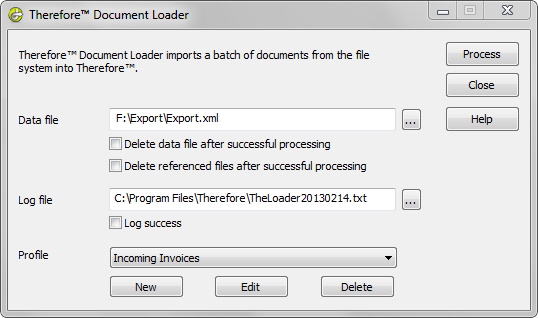
8.Indiquez l'emplacement du fichier de données à importer, ainsi que celui du fichier Log. Sélectionnez ensuite le profil approprié. Vous trouverez dans Références des informations détaillées relatives aux cases à cocher. Cliquez sur Processus pour démarrer l'importation des fichiers.
9.Lorsque tous les documents ont été importés, démarrez Therefore™ Navigator, puis recherchez, extrayez et affichez quelques documents pour vous assurer que l'opération s'est déroulée normalement.

