
|
Dateiprofil |
Scroll |

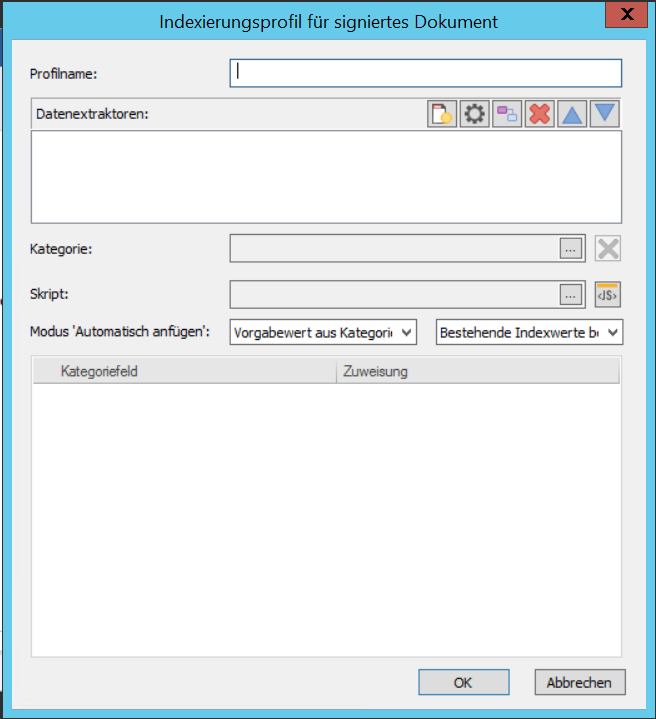
Profilname:
Der Name des Profils.
Filter
Sie können einen Filter einrichten, um bestimmte Dateien ein- bzw. auszuschließen. Beispiel:
File.Name<>"Vorlage.pdf" verarbeitet keine Dateien mit dem Namen "Vorlage.pdf".
File.Extension="pdf" verarbeitet nur PDF-Dateien.
|
Platzhalter werden hier nicht unterstützt, aber Profile, die mit dem Therefore™ Content Connector verwendet werden, können einen zweiten Filter enthalten, der die Dateien innerhalb eines Eingabeordners analysiert. Dieser Auftragsfilter unterstützt auch Platzhalter. |

Mit Datenextraktoren können Daten aus verschiedenen Quellen extrahiert werden.
Um einen neuen Datenextraktor zu erstellen, klicken Sie auf  .
.
Um einen bestehenden Extraktor zu bearbeiten, klicken Sie auf  .
.
Wenn mehrere Extraktoren definiert sind, können Sie die Ausführungsreihenfolge ändern, indem Sie die Extraktoren in der Liste nach oben bzw. unten verschieben

Um die Ausgabe eines vorherigen Datenextraktors zu verwenden, klicken Sie auf  .
.
Um einen Datenextraktor zu entfernen, klicken Sie auf  .
.
Datenextraktortypen
PDF-Datenextraktor
Extrahiert Daten aus einer PDF- oder PDF/A-Datei.
XML-Datenextraktor
Extrahiert Daten aus einer XML-Datei.
Text-Zeile-Datenextraktor
Extrahiert Text aus einer einzelnen Zeile in einer Textdatei (ASCII-Zeichen, z. B. .txt, .csv, .dat).
Text-Seite-Datenextraktor
Extrahiert Text aus einer Textdatei (ASCII-Zeichen, z. B. .txt, .csv, .dat), die mehrere Seiten enthält.
Barcode- und OCR-Datenextraktor
Extrahiert Barcode- und OCR-Daten aus einem Dokument.
ZIP-Datenextraktor:
Verarbeitet ZIP-Dateien und extrahiert die darin enthaltenen Daten. Die extrahierten Dateien können in anderen Datenextraktoren verwendet werden.
Kategorie:
Sie müssen die Kategorie angeben, in der die Dateien gespeichert werden sollen.
Skript
Sie können ein Initialisierungskript erstellen, das vor der Feldzuweisung ausgeführt wird.
Automatischer Anfügemodus
Der automatische Anfügemodus für Dokumente, die mit diesem Profil gespeichert werden, kann durch Auswahl einer Option aus der Dropdownliste festgelegt werden.
Legen Sie das Verhalten in Bezug auf Indexdaten im bestehenden und im resultierenden Dokument fest, indem Sie eine Option aus der zweiten Dropdownliste auswählen. Die Standardeinstellung ist "Bestehende Indexwerte beibehalten".
Bestehende Indexwerte beibehalten: Die Indexdaten des resultierenden Dokuments werden aus dem bestehenden Dokument übernommen. Felder, die im bestehenden Dokument leer sind, erhalten ihren Wert aus dem neuen Dokument.
Indexwerte überschreiben: Die Indexdaten des resultierenden Dokuments werden aus dem neuen Dokument übernommen. Leere Felder werden aus dem bestehenden Dokument befüllt.
Nachdem Sie eine Kategorie ausgewählt haben, wird eine Liste der Indexfelder angezeigt. Wenn Sie auf den Dropdownpfeil von "Zuweisung" klicken, wird eine Liste von Zuweisungsvariablen angezeigt. Durch Klicken auf die Schaltfläche "Durchsuchen" wird ein Dialogfeld geöffnet, in dem Sie die Validierung und die Fehlerbehandlung konfigurieren können.
Test
Das Indexierungsprofil kann über eine Beispieldatei getestet werden.
