
|
Profil de fichier |
Scroll |

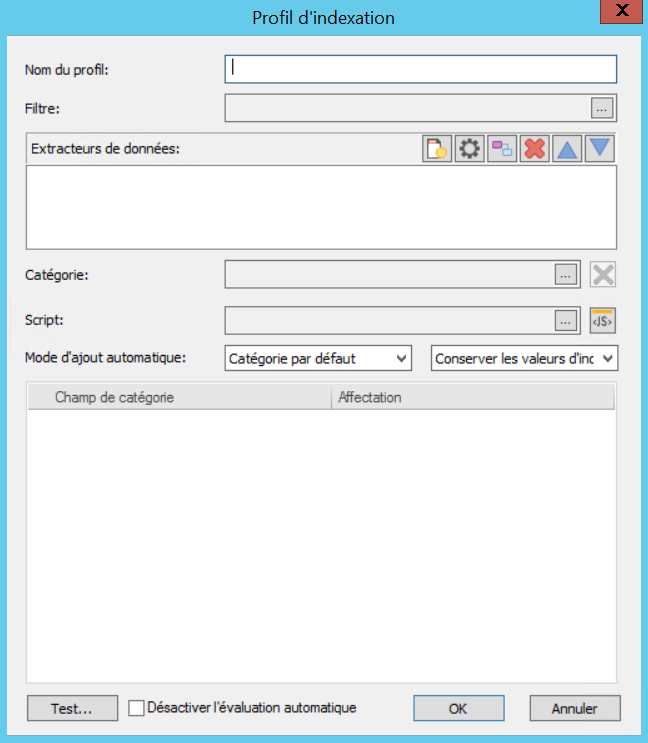
Nom du profil :
Ce champ contient le nom du profil.
Filtre :
La création d'un filtre permet d'exclure ou d'inclure des fichiers. Exemple :
File.Name<>"Gabarit.pdf" ne traite aucun fichier intitulé « Gabarit.pdf ».
File.Extension="pdf" ne traite que les fichiers PDF.
|
Les caractères génériques ne sont pas pris en charge, mais les profils associés à Therefore™ Content Connector peuvent également contenir un second filtre qui analyse les fichiers au sein d'un répertoire d'entrée. Ce filtre de travail gère également les caractères génériques. |

Les extracteurs de données permettent d'extraire les données de sources diverses.
Pour créer un extracteur de données, cliquez sur 
Pour modifier un extracteur de données, cliquez sur 
Si plusieurs extracteurs de données ont été définis, décalez-les vers le haut ou vers le bas dans la liste pour en modifier l'ordre d'exécution

Pour utiliser la sortie d'un extracteur de données antérieur, cliquez sur 
Pour supprimer un extracteur de données, cliquez sur 
Types d'extracteur de données :
Extracteur de données PDF :
Extrait les données d’un fichier PDF ou PDF/A.
Extracteur de données XML :
Extrait les données d’un fichier XML.
Extracteur de données de ligne de texte :
Extrait les données d'une ligne unique dans un fichier texte brut (contenant des caractères ASCII, txt, csv ou dat, par exemple).
Extracteur de données de page de texte :
Extrait les données d'un fichier texte (contenant des caractères ASCII, txt, csv ou dat, par exemple) de plusieurs pages dans un document unique.
Code à barres et extracteur de données ROC :
Extrait les données de types codes à barres et ROC d'un document.
Extracteur de données ZIP :
Traite les fichiers ZIP et extrait les données qu’ils contiennent. Les fichiers extraits peuvent être utilisés par d’autres extracteurs de données.
Catégorie :
Indiquez la catégorie dans laquelle doivent être mémorisés les fichiers.
Script :
Vous pouvez créer un script d'initialisation, qui sera exécuté avant l'exécution de l'affectation des champs.
Mode d'ajout automatique :
Vous pouvez définir le mode d'ajout automatique associé aux documents mémorisés avec ce profil en sélectionnant une option dans le menu déroulant.
Définissez le comportement relatif aux données d'index dans le document existant et résultant en sélectionnant une option dans le second menu déroulant. L’option « Conserver les valeurs d'index existantes » est activée par défaut.
Conserver les valeurs d'index existantes : les données d’index du document résultant sont extraites du document existant. La valeur de tout champ vide dans le document existant est issue du nouveau document.
Écraser les valeurs d'index : les données d’index du document résultant sont extraites du nouveau document. Les champs vides sont renseignés à partir du document existant.
Une fois la catégorie sélectionnée, une liste de champs d'index s'affiche. Cliquez sur la flèche vers le bas associée aux affectations pour afficher la liste des variables correspondantes. Cliquez sur le bouton Parcourir pour ouvrir une boîte de dialogue permettant de configurer la validation et la gestion des erreurs.
Test
Vous pouvez tester le profil d'indexation à l'aide d'un exemple de fichier.
